Releases: QoderAI/blog
Repo Wiki: Surfacing Implicit Knowledge
desc: Turn code into living, shared documentation.
category: Product
img: https://img.alicdn.com/imgextra/i2/O1CN01c6LKGp1NGHqns4lxb_!!6000000001542-0-tps-1712-1152.jpg
time: September 11, 2025 · 3min read
What can Repo Wiki do for you?
Repo Wiki automatically generates a structured documentation knowledge base for your project based on your code, covering project architecture, dependency diagrams, technical documentation, and other content while continuously tracking changes in both code and documentation. It transforms experiential knowledge hidden in code into explicit knowledge that can be shared across teams, converting experience into reusable project assets. When developing with Qoder, Repo Wiki can help in:
- Improving collaboration efficiency with Agents
Structured and complete engineering knowledge enables Agents to better understand context and provide you with more accurate, detailed answers, significantly boosting development efficiency.
- Quickly learning about projects
By reviewing clear engineering documentation, you can quickly grasp project structure and implementation details, easily get started with development.
How is Repo Wiki generated?
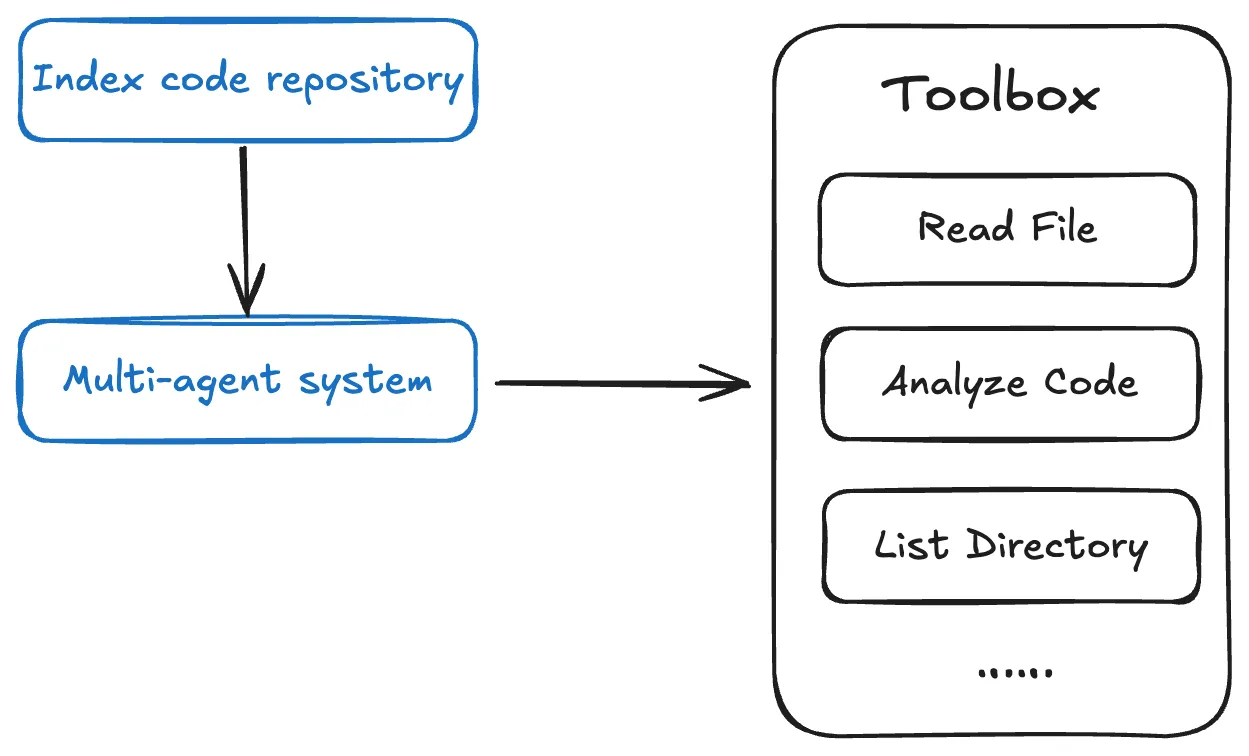
Repo Wiki utilizes a multi-Agent architecture, generating project knowledge in phases.
-
Repo Wiki automatically establishes an index for the code repository, thereby providing Agents with strong codebase awareness through its tools.
-
The multi-Agent system analyzes and models the code repository, plans documentation structure, balances knowledge depth with reading efficiency, and appropriately captures project knowledge across various types of documentation.
How is Repo Wiki maintained and shared?
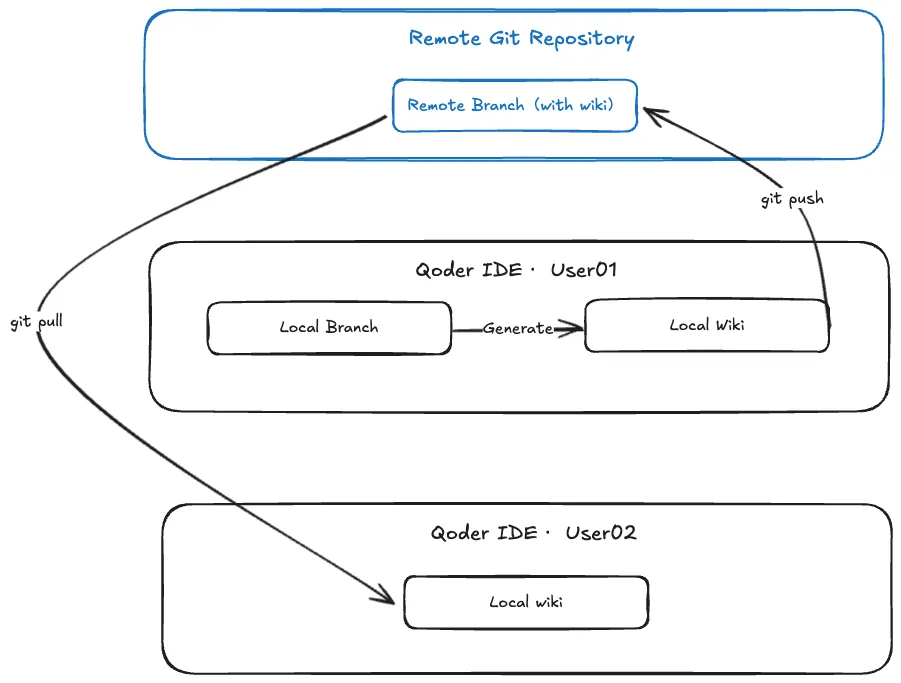
Wiki sharing
Wiki sharing is offered to share project knowledge within the team. When you generate a Wiki locally, the directory (.qoder/repowiki) is automatically created in your code repository. Simply pushing this directory to the remote repository allows you to easily share the generated Wiki with team members.
Content maintenance and export
To ensure the Wiki remains consistent with the code, the system automatically detects code changes and prompts you to update the related Wiki.
Also, self-maintenance is supported. You can modify files in the Wiki directory (.qoder/repowiki) and synchronize changes back to the Wiki by yourself.
Best practices
Get better AI chat responses
-
When querying about code repositories, the Agent will quickly respond. It automatically consults the relevant Wiki, combining contextual information to provide accurate code explanations, relevant technical documentation, and implementation details.
-
When adding features or fixing bugs, the Agent automatically consults Repo Wiki, combining real-time project learning to provide solutions that align with the project architecture. This ensures new code maintains consistency with the existing system while improving development efficiency.
Learn about code faster
- Through Repo Wiki, you can quickly learn about the project's overall architecture, module dependencies, and technical implementation details, as Repo Wiki provides a structured knowledge base, including project architecture descriptions, dependency diagrams, and detailed technical documentation.
Qwen-Coder-Qoder: Customizing a fast-evolving frontier model for real software
desc: Inside Qwen-Coder-Qoder: The RL-optimized model behind Qoder's agent architecture
category: Product
img: https://img.alicdn.com/imgextra/i3/O1CN01fbHceT1K4t9NQua1T_!!6000000001111-2-tps-1712-1152.png
time: February 1, 2026 · 5 min read
Introduction
Today, we are pleased to introduce Qwen-Coder-Qoder, a customized model tailored to elevate the end-to-end agentic coding experience on Qoder.
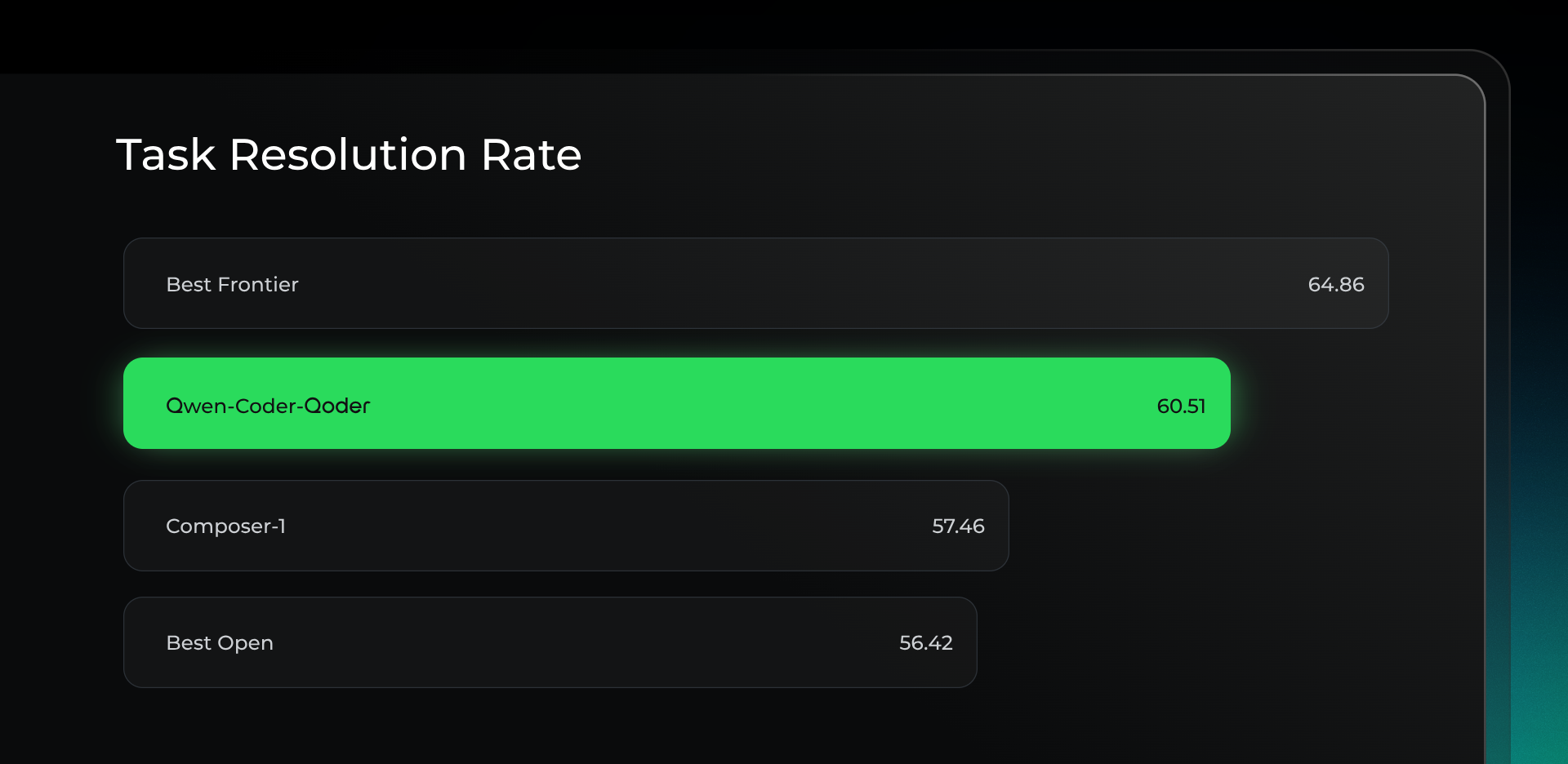
Built upon the Qwen-Coder foundation, Qwen-Coder-Qoder has been optimized with large-scale reinforcement learning to align tightly with Qoder's scenarios, tools, and agent architecture. On Qoder Bench — our benchmark for real-world software engineering tasks — it surpasses Cursor Composer-1 in task resolution performance. The gains are particularly notable on Windows, where terminal command accuracy is improved by up to 50%.
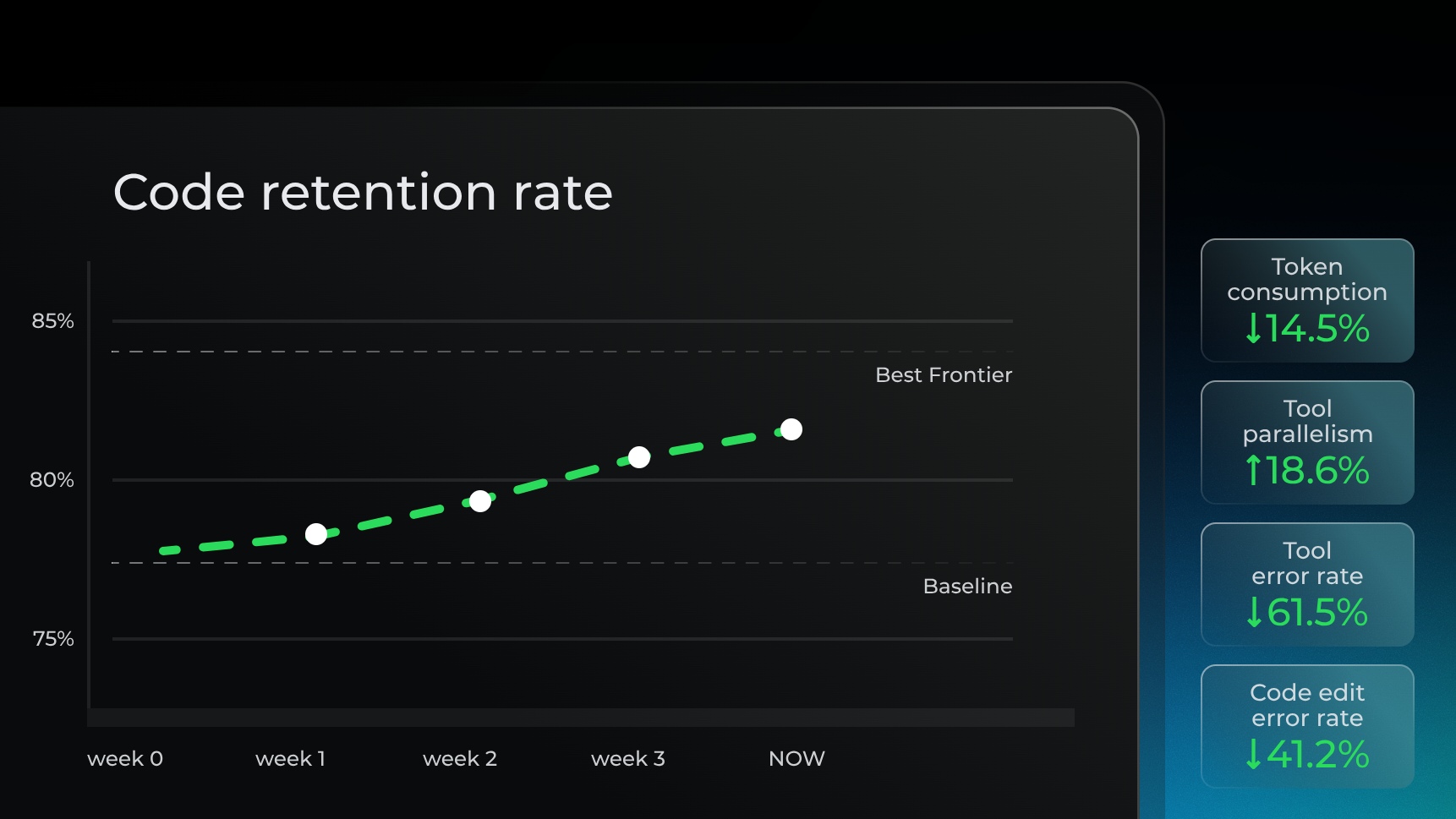
At the same time, Qwen-Coder-Qoder has delivered tangible, data-backed improvements to the Qoder user experience. With rapid model iterations, we have observed meaningful gains in production over the past few weeks: code retention has increased by 3.85%, tool error rates have dropped by 61.5%, and token consumption has decreased by 14.5%. These metrics now position Qoder alongside the world's top-tier models.
Beyond superior performance metrics, Qwen-Coder-Qoder reflects the 'taste' and 'mindset' of a senior software engineer. We believe a great AI coding partner shouldn't just solve problems—it should solve them elegantly and masterfully.
- Adheres to best engineering practices: Many general models optimize solely for task resolution and may take shortcuts that bypass established engineering conventions. In contrast, Qwen-Coder-Qoder is trained to follow rigorous software engineering principles, maintain consistent project code style, and ensure production-ready outputs.
- Holistic Repository Understanding: By leveraging Qoder's unique context systems — including code graphs, project memory, and Repo Wiki — Qwen-Coder-Qoder understands the project from a global perspective and uses the right tools to complete tasks with precision.
- High-Efficiency Parallelism: The model recognizes tasks that don't depend on each other and runs them parallelly — whether it's fetching code, planning tasks, or making multiple edits. This makes the entire workflow much faster.
- Resilient Problem Solving: When faced with complex or stubborn issues, general models may abandon the task after limited attempts. Qwen-Coder-Qoder demonstrates a developer-level persistence: it refines its approach iteratively and stays engaged until the problem is resolved.
Our Vision: A "Model-Agent-Product" Flywheel for Co-evolving Intelligence
Qwen-Coder-Qoder is not an accident — it is the inevitable outcome of the intelligent evolution loop we've built around the Model-Agent-Product paradigm.
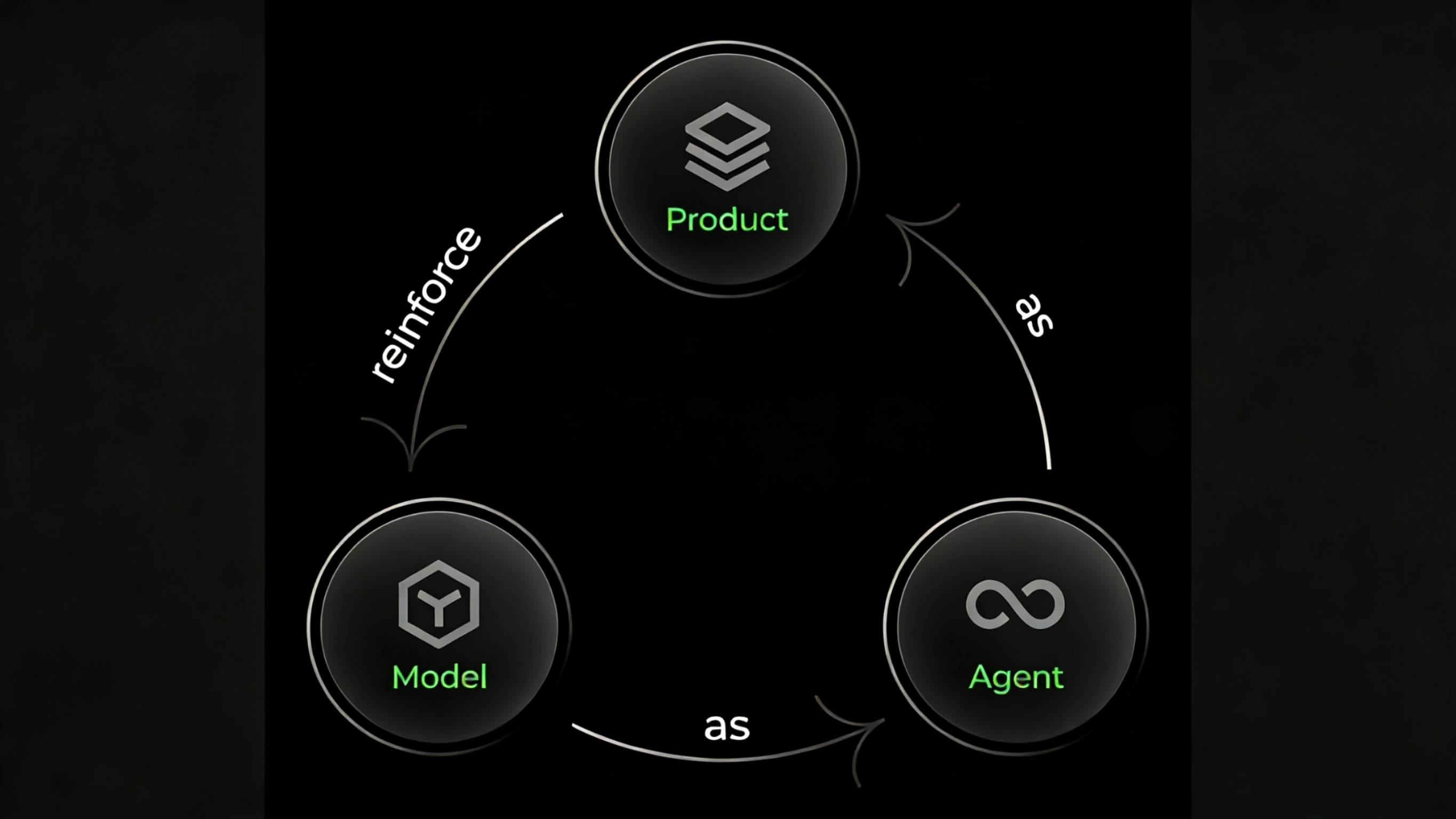
In the rapidly evolving landscape of AI coding, we've focused on building a self-evolving cycle: Model → Agent → Product (model as agent, agent as product, product reinforces model). This loop ensures that insights from real user interactions continuously inform and enhance our models' capabilities. At the core of this system, the model provides the foundation — we embed all of the capabilities required by the Qoder Agent directly into Qwen-Coder-Qoder, which powers task execution. On the product side, the Agent is central — every feature and workflow in Qoder revolves around it. With thousands of users engaging with the product daily, we capture real-world usage patterns and preferences, extract best software engineering practices, and convert them into reward signals that further strengthen our RL training.
This completes our flywheel of software engineering intelligence. Qwen-Coder-Qoder is a large-scale RL model trained on real-world product environments, real-world development tasks, and real-world rewards.
Under the Hood: How We Made It Happen
Achieving these results requires a robust, state-of-the-art training strategy built on three core elements:
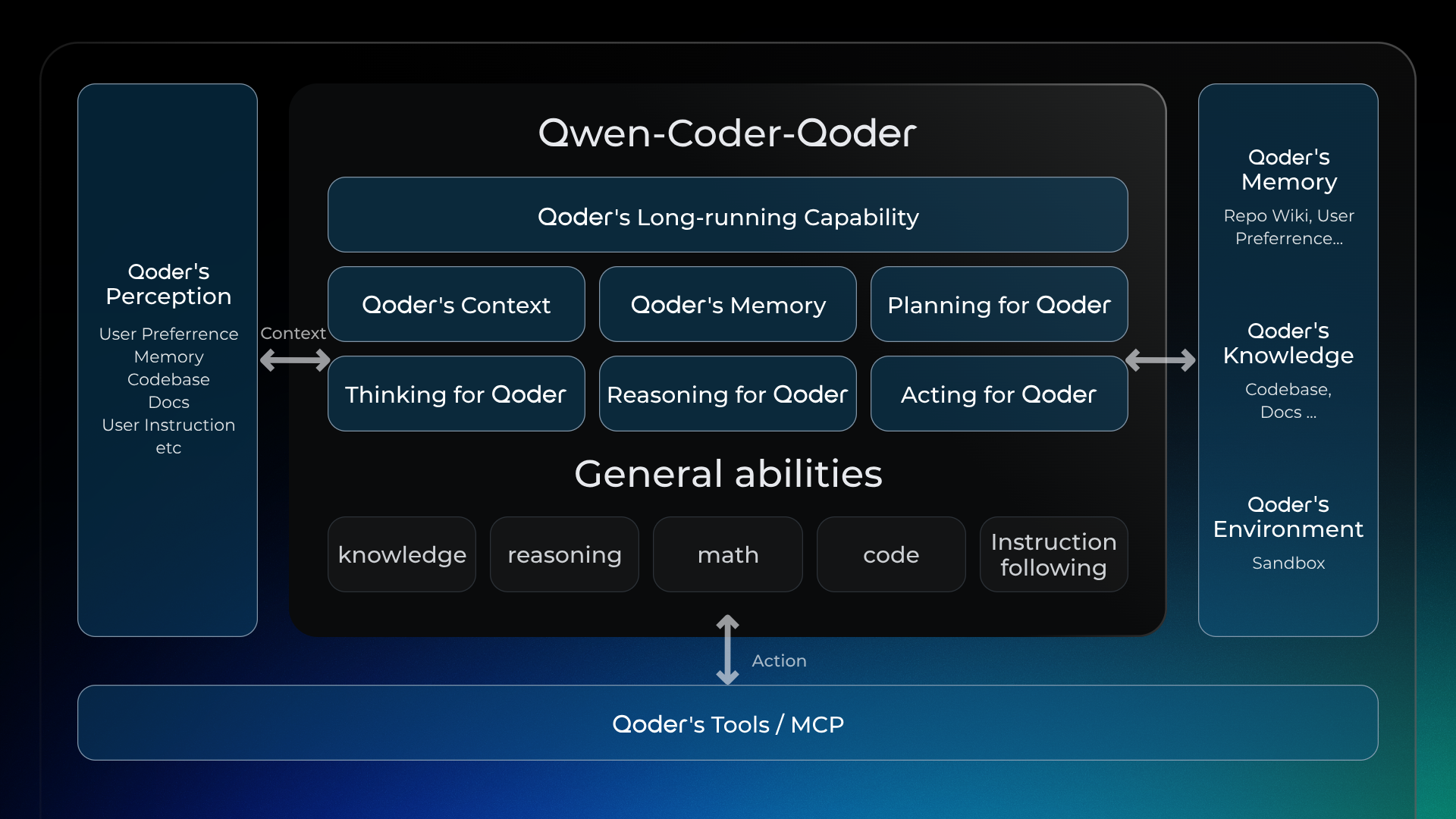
A Real-World Qoder Agent as the Sandbox
We train the model to master the full stack of Qoder's Knowledge, Memory, Tools/MCP, and Context to solve real-world coding tasks. Unlike general-purpose models, our model is tightly aligned with the Qoder product. As the model continues to evolve, this synergy is unlocking massive value. To scale this, we've automated the setup of tens of thousands of real-world software environments. Using High-speed containerization, we can spin up and tear down these sandboxes instantly to power our reinforcement learning at massive scale.
Real-World Best Engineering Practices as Reward Signals
In agentic reinforcement learning, reward signals are critical to guiding the model toward desirable behaviors. We use several criterias to verify correctness including unit tests, CLI checks, and custom checklists to make sure the agent actually gets the job done. It's not just about getting a passing diff patch. We also enforce strict rules on how the code is written, ensuring the entire process follows professional engineering standards. we ensure the agent's output meets the same standards you'd expect from a senior engineer.
Reward hacking is an inherent challenge in reinforcement learning. For instance, if we reward the model for parallel tool use to boost speed, it might try to 'game the system' by scanning tons of irrelevant files just to rack up points. While the parallelism metrics look great, there's no real contribution to the final accuracy.
Solving Reward Hacking is essentially a battle of wits with the model. To tackle this, we built a 'Rewarder-Attacker' adversarial framework. We use an LLM as a reviewer to constantly stress-test and 'attack' our reward system, hunting for loopholes before training even begins. This setup has drastically improved both the iteration speed and the robustness of our reward design.
Large-Scale, High-Efficiency RL Training Framework
Qwen-Coder-Qoder is powered by ROLL, which is optimized to enable efficient RL training of MoE LLMs with hundreds of billions of parameters on clusters scaled to thousands of GPUs. In a typical RL loop, the rollout phase often consumes over 70% of the total time. To maximize end-to-end throughput, we optimized the system from two angles:
- Optimizing the Rollout Phase: We implemented asynchronous scheduling to minimize idle time, Prefix/KV cache reuse to eliminate redundant compute, and redundant environment execution to mitigate long-tail latency.
- Rollout-Training Co-design: We decoupled the two by relaxing on-policy constraints to allow cross-version sampling. By running training and rollout in parallel, we implemented dynamic resource yielding, ensuring that GPUs are surrendered to rollout during training wait times.
Together, these system-level optimizations delivered a 10x boost in throughput, significantly compressing our training cycles.
Future Prospects
The Qwen-Coder-Qoder we're releasing today is the first milestone of our "Model-Agent-Product" flywheel. In just a few short months, we've already witnessed how this loop can drastically elevate the end-to-end experience.
This is just the beginning. Doubling down on this trajectory, we will continue to evolve through weekly iterations, refining model efficacy and experience as we forge ahead toward an 'Agentic Coding Platform for Real Software'.
Quest Remote: Delegate Tasks to Cloud as Effortlessly as Sending an Email
desc: Let the cloud handle the routine and free your mind for what matters.
img: https://img.alicdn.com/imgextra/i4/O1CN01rVNSWR22RBWIKqmk8_!!6000000007116-2-tps-1712-1152.png
category: Feature
time: October 22, 2025 · 3min read
Qoder’s flagship feature, the Quest Mode, has now reached a major milestone with the launch of the all-new "Remote Delegation" capability. This upgrade empowers developers to outsource complex, time-consuming development tasks to a secure, cloud-based sandbox environment for asynchronous execution, and fully liberates local computing resources. Therefore, developers can finally break free from tedious background operations and refocus on the pure joy and value of coding. Qoder delivers a more efficient and secure AI-native development experience to developers worldwide.
What is Remote Delegation?
Before diving into remote delegation, let’s revisit the core philosophy behind Quest: Task Delegation. In Qoder, every development requirement—large or small—is abstracted into a "Quest". A Quest could range from bug fixes and feature developments to major code refactoring. Traditionally, developers must personally handle each step of the Quest lifecycle.
Quest Mode, introduces a highly capable coding agent, elevating developers from "executors" to "commander". You simply interact with the agent locally to generate the task specification (Spec), which then guides the agent to autonomously handle the development process. This means developers need only express intent clearly; the system will formulate an execution plan and perform the tasks. Previously, Quest tasks are delegated mainly to local agents for code generation and automated testing. This helps improving coding efficiency—but constraints in environment setup, resources, and security remains.
Now, with Remote Delegation, Qoder fully extends the delegation paradigm from the local machine to the cloud.
How Remote Delegation Works
Imagine you’re facing an extremely challenging task: upgrading dependencies and refactoring the performance of a massive codebase. In the past, this meant cloning the entire repository, dealing with outdated dependencies, and then getting ready for an unpredictable, time-consuming battle—all on your local machine.
With Qoder’s Remote Delegation, your workflow becomes dramatically more streamlined:
-
Create a Quest
Describe your task objectives in natural language within Qoder to create a new Quest. -
Generate a Design Document
Qoder automatically crafts a detailed design document for your Quest through interactive dialogue. -
One-Click Delegation
Once you’ve reviewed and approved the design document, simply click "Start" to send the task to the cloud for execution. -
Refocus Your Attention
You’re now free to concentrate on creative, high-impact work.
Under the Hood
The moment you delegate a task, Qoder performs all of the following:
-
Intelligent Environment Provisioning
Qoder instantly creates an isolated, secure, and high-performance sandbox in the cloud. It automatically analyzes your project, detects required runtime environments, language versions, toolchains, and dependencies, and preconfigures everything. -
Asynchronous Task Execution
A powerful cloud-based agent takes the helm, tackling your task like a seasoned developer: cloning code, analyzing dependencies, upgrading packages, compiling, trouble shooting, bug fixing, iterative testing, and more—all executed asynchronously and efficiently in the cloud. -
Real-Time Progress Tracking
Within Qoder IDE, you can monitor task progress in real time, much like tracking a parcel: view current steps, obstacles encountered, and solutions the AI agent is attempting—all at a glance. -
Seamless Human-AI Collaboration
If the cloud agent encounters a challenge it cannot resolve autonomously, the task is paused and Qoder notifies you for input. You can review the context within the IDE, provide guidance, and let the agent continue. -
Review and Merge Results
Once the Quest is complete, Qoder delivers a comprehensive report—including a summary and code changes—and submits the final result as a Pull Request to your repository, ready for your review and merge.
Core Value of Remote Delegation
Quest Remote brings transformative benefits to developers:
-
Unleash Productivity:
Delegate repetitive, resource-intensive tasks to the cloud, freeing your focus for creative work—ideation, design, and innovation. -
Accelerate Learning and Exploration:
Want to experiment with a new technology or framework? Skip the local setup. Delegate with a click and instantly validate your ideas in a cloud sandbox, dramatically lowering the barrier to new tech adoption. -
Extend Your Reach:
Once delegated to a Remote Agent, your tasks keep progressing in the cloud—even when your laptop is closed—expanding the time and space boundaries of AI-powered coding. -
Embrace the Future:
Remote Delegation fundamentally reimagines development workflows for a cloud-native era, aligning the coding process with real deployment environments—ushering in true DevOps and modern cloud-native culture.
Let the cloud handle the routine and free your mind for what matters. Upgrade Qoder and experience the future of development with Quest Remote!
Quest 1.0: Refactoring the Agent with the Agent
desc: Tokens Produce Deliverables, Not Just Code
category: Technology
img: https://img.alicdn.com/imgextra/i2/O1CN01dz3f931IyBjmbJ4B0_!!6000000000961-2-tps-1712-1152.png
time: January 15, 2026 · 8 min read
Last week, the Qoder Quest team accomplished a complex 26-hour task using Quest 1.0: refactoring its own long-running task execution logic. This wasn't a simple feature iteration, as it involved optimizing interaction flows, managing mid-layer state, adjusting the Agent Loop logic, and validating long-running task execution capabilities.
From requirement definition to merging code into the main branch, the Qoder Quest team only did three things: described the requirements, reviewed the final code, and verified the experimental results.
This is the definition of autonomous programming: AI doesn't just assist or pair. It autonomously completes tasks.
Tokens Produce Deliverables, Not Just Code
Copilot can autocomplete code, but you need to confirm line by line. Cursor or Claude Code can refactor logic, but debugging and handling errors is still your job. These tools improve efficiency, but humans remain the primary executor.
The problem Quest solves is this: Tokens must produce deliverable results. If AI writes code and a human still needs to debug, test, and backstop, the value of those tokens is heavily discounted. Autonomous programming is only achieved when AI can consistently produce complete, runnable, deliverable results.
Agent Effectiveness = Model Capability × Architecture
From engineering practice, we've distilled a formula:
Agent Effectiveness = Model Capability × Agent Architecture (Context + Tools + Agent Loop)
Model capability is the foundation, but the same model performs vastly differently under different architectures. Quest optimizes architecture across three dimensions: context management, tool selection, and Agent Loop, to fully unleash model potential.
Context Management: Agentic, Not Mechanical
As tasks progress, conversations balloon. Keeping everything drowns the model; mechanical truncation loses critical information. Quest employs "Agentic Context Management": letting the model autonomously decide when to compress and summarize.
Model-Driven Compression
In long-running tasks, Quest lets the model summarize completed work at appropriate moments. This isn't "keep the last N conversation turns"; it's letting the model understand which information matters for subsequent tasks and what can be compressed.
Compression triggers based on multiple factors:
-
Conversation rounds reaching a threshold
-
Context length approaching limits
-
Task phase transitions (e.g., from exploring to implementation)
-
Model detection of context redundancy
The model makes autonomous decisions based on current task state, rather than mechanically following fixed rules.
Dynamic Reminder Mechanism
The traditional approach hardcodes all considerations into the system prompt. But this bloats the prompt, scatters model attention, and tanks cache hit rates.
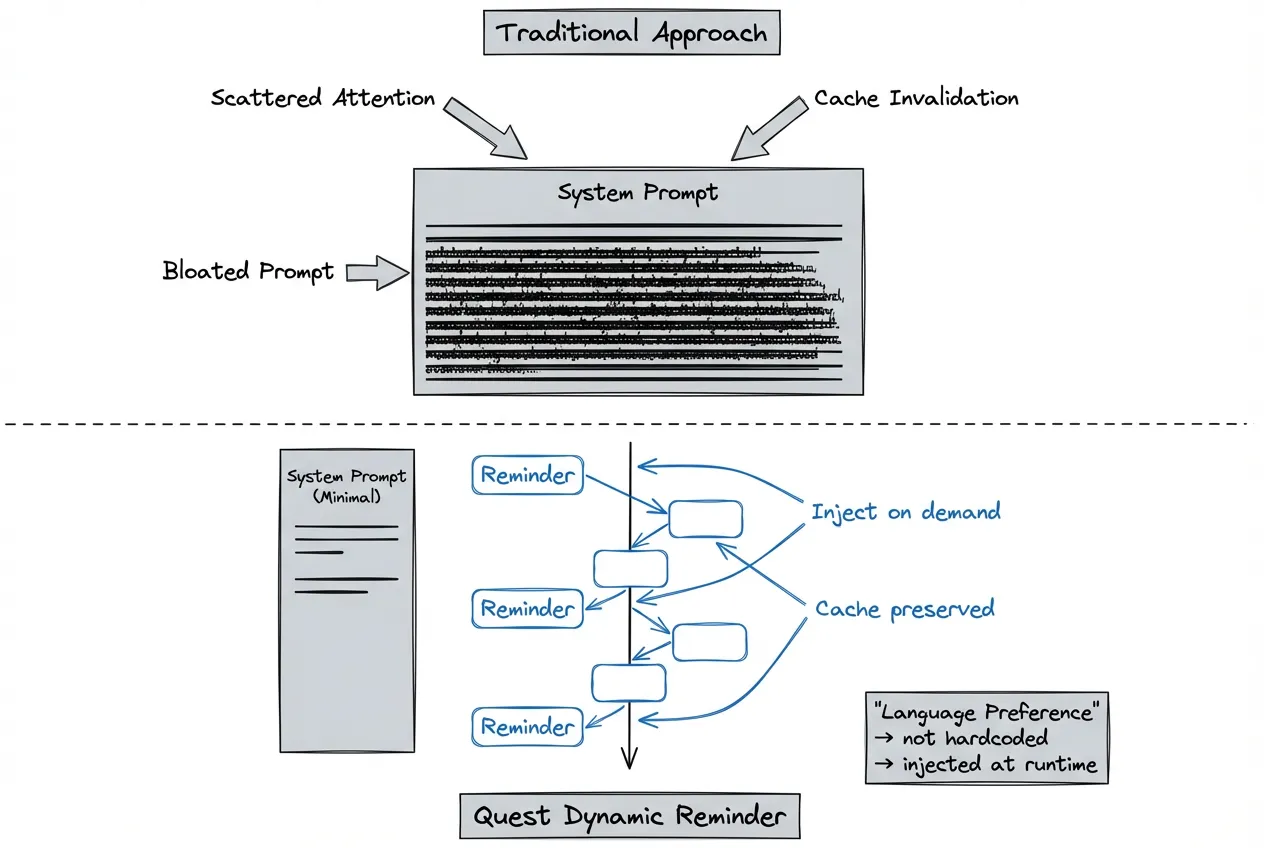
Take language preference as an example:
Traditional approach: System prompt hardcodes "Reply in Japanese." Every time a user switches languages, the entire prompt cache invalidates, multiplying costs.
Quest approach: Dynamically inject context that needs attention through the Reminder mechanism. Language preferences, project specs, temporary constraints—all added to conversations as needed. This ensures timely information delivery while avoiding infinite system prompt bloat.
Benefits:
-
Improved cache hit rates, reduced inference costs
-
Lean system prompts, enhanced model attention
-
Flexible adaptation to different scenario requirements
Tool Selection: Why Bash is the Ultimate Partner
If we could only keep one tool, it would be Bash. This decision may seem counterintuitive. Most agents on the market offer rich specialized tools: file I/O, code search, Git operations, etc. But increasing tool count raises model selection complexity and error probability.
Three Advantages of Bash
Comprehensive. Bash handles virtually all system-level operations: file management, process control, network requests, text processing, Git operations. One tool covers most scenarios—the model doesn't need to choose among dozens.
Programmable and Composable. Pipelines, redirects, and scripting mechanisms let simple commands compose into complex workflows. This aligns perfectly with Agent task decomposition: break large tasks into small steps, complete each with one or a few commands.
Native Model Familiarity. LLMs have seen vast amounts of Unix commands and shell scripts during pre-training. When problems arise, models can often find solutions themselves without detailed prompt instructions.
Less is More
Quest still maintains a few fixed tools, mainly for security isolation and IDE collaboration. But the principle remains: if Bash can solve it, don't build a new tool.
Every additional tool increases the model's selection burden and error potential. A lean toolset actually makes the Agent more stable and predictable. Through repeated experimentation, after removing redundant specialized tools, task completion rates remained the same level while context token consumption dropped by 12%.
Agent Loop: Spec -> Coding -> Verify
Autonomous programming's Coding Agent needs a complete closed loop: gather context > formulate plan > execute coding > verify results > iterate optimization.
Observing coding agents in the market, users most often say "just run it...", "make it work", "help me fix this error." This exposes a critical weakness: they're cutting corners on verification. AI writes code, humans test it - that's not autonomous programming.
Spec-Driven Development Flow
Spec Phase: Clarify requirements before starting, define acceptance criteria. For complex tasks, Quest generates detailed technical specifications, ensuring both parties agree on the definition of "done."
Spec elements include:
-
Feature description: What functionality to implement
-
Acceptance criteria: How to judge completion
-
Technical constraints: Which tech stacks to use, which specifications to follow
-
Testing requirements: Which tests must pass
Coding Phase: Implement functionality according to Spec. Quest proceeds autonomously in this phase, without continuous user supervision.
Verify Phase: Automatically run tests, verify implementation meets Spec. Verification types include syntax checks, unit tests, integration tests, etc. If criteria aren't met, automatically enter the next iteration rather than throwing the problem back to the user.
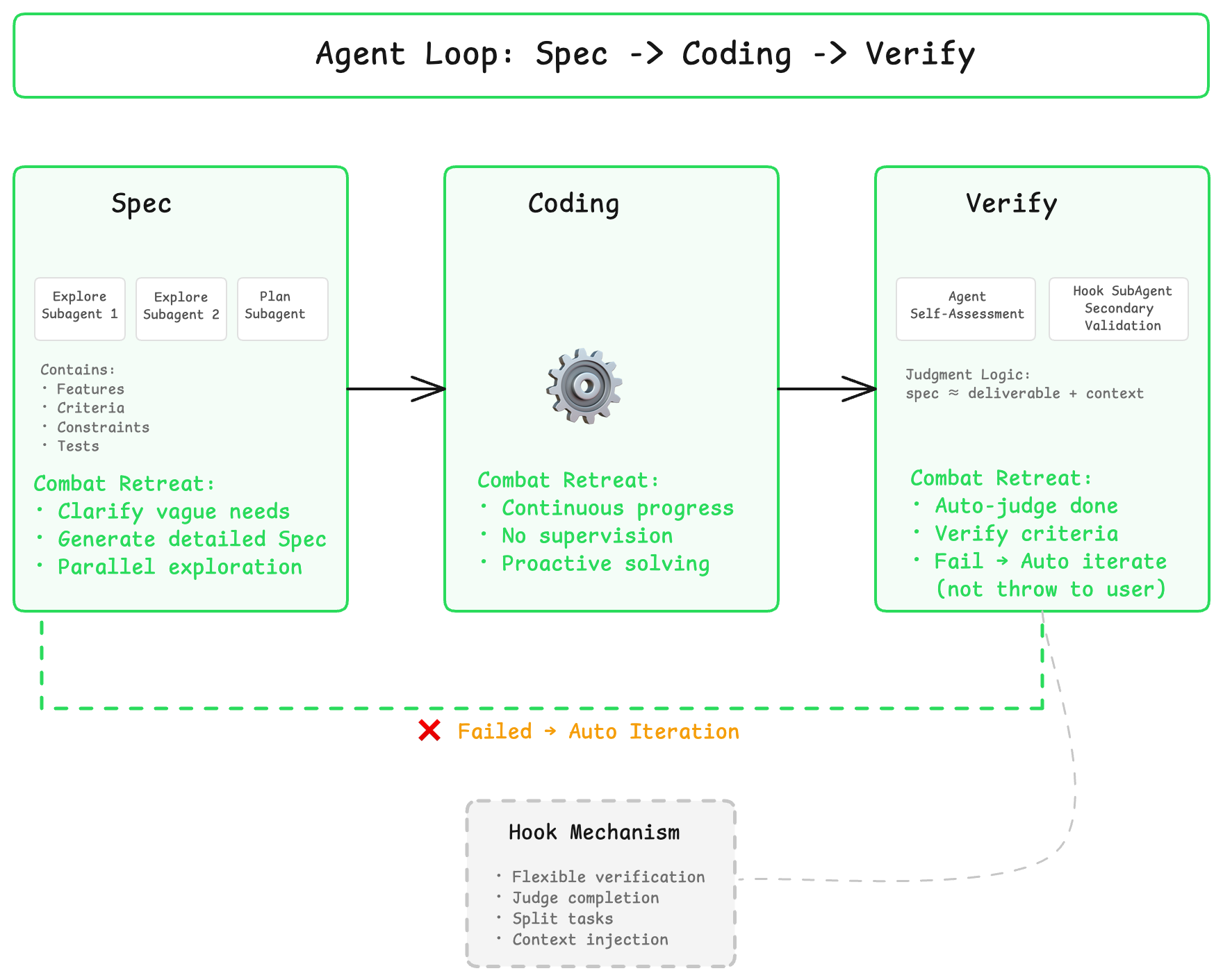
Through the Hook mechanism, these three phases can be flexibly extended and combined. For example, integrate custom testing frameworks or lint rules in the Verify phase, ensuring every delivery meets team engineering standards.
Combating Model "Regress" Tendency
Most current models are trained for ChatBot scenarios. Facing long contexts or complex tasks, they tend to "regress", giving vague answers or asking for more information to delay execution.
Quest's architecture helps models overcome this tendency: injecting necessary context and instructions at appropriate moments, pushing models to complete the full task chain rather than giving up midway or dumping problems back on users.
Auto-Adapt to Complexity, Not Feature Bloat
Quest doesn't just handle code completion. It manages complete engineering tasks. These tasks may involve multiple modules, multiple tech stacks, and require long-running sustained progress.
The design principle: automatically adapt strategy based on task complexity. Users don't need to care about how scheduling works behind the scenes.
Dynamic Skills Loading
When tasks involve specific frameworks or tools, Quest dynamically loads corresponding Skills. Skills encapsulate validated engineering practices, such as:
-
TypeScript configuration best practices
-
React state management patterns
-
Common database indexing pitfalls
-
API design specifications
This isn't making the model reason from scratch every time—it's directly reusing accumulated experience.
Teams can also encapsulate engineering specs into Skills, making Quest work the team's way. Examples:
-
Code style guides
-
Git commit conventions
-
Test coverage requirements
-
Security review checklists
Intelligent Model Routing
When a single model's capabilities don't cover task requirements, Quest automatically orchestrates multiple models to collaborate. Some models excel at reasoning, others at writing, others at handling long contexts.
Intelligent routing selects the most suitable model based on subtask characteristics. To users, it's always just one Quest.
Multi-Agent Architecture
When tasks are complex enough to require parallel progress and modular handling, Quest launches multi-agent architecture: the main Agent handles planning and coordination, subagents execute specific tasks, companion Agents supervise. But we use this capability with restraint. Multi-agent isn't a silver bullet because context transfer has loss, and task decomposition has high barriers. We only enable it when truly necessary.
Designed for Future Models
From day one, Quest has been designed for SOTA models. The architecture doesn't patch for past models. It ensures that as underlying model capabilities impr...
Quest Mode: Task Delegation to Agents
desc: Introducing Quest Mode. Your new AI-assisted coding workflow.
time: August 21, 2025 · 3 min read
category: Product
img: https://img.alicdn.com/imgextra/i4/O1CN0103AFeh1vZhZmtD0wg_!!6000000006187-0-tps-1712-1152.jpg
With the rapid advancement of LLMs—especially following the release of the Claude 4 series—we've seen a dramatic improvement in their ability to handle complex, long-running tasks. More and more developers are now accustomed to describing intricate features, bug fixes, refactoring, or testing tasks in natural language, then letting the AI explore solutions autonomously over time. This new workflow has significantly boosted the efficiency of AI-assisted coding, driven by three key shifts:
-
Clear software design descriptions allow LLMs to fully grasp developer intent and stay focused on the goal, greatly improving code generation quality.
-
Developers can now design logic and fine-tune functionalities using natural language, freeing them from code details.
-
The asynchronous workflow eliminates the need for constant back-and-forth with the AI, enabling a multi-threaded approach that delivers exponential gains in productivity.
We believe these changes mark the beginning of a new paradigm in software development—one that overcomes the scalability limitations of “vibe coding” in complex projects and ushers in the era of natural language programming. In Qoder, we call this approach Quest Mode: a completely new AI-assisted coding workflow.
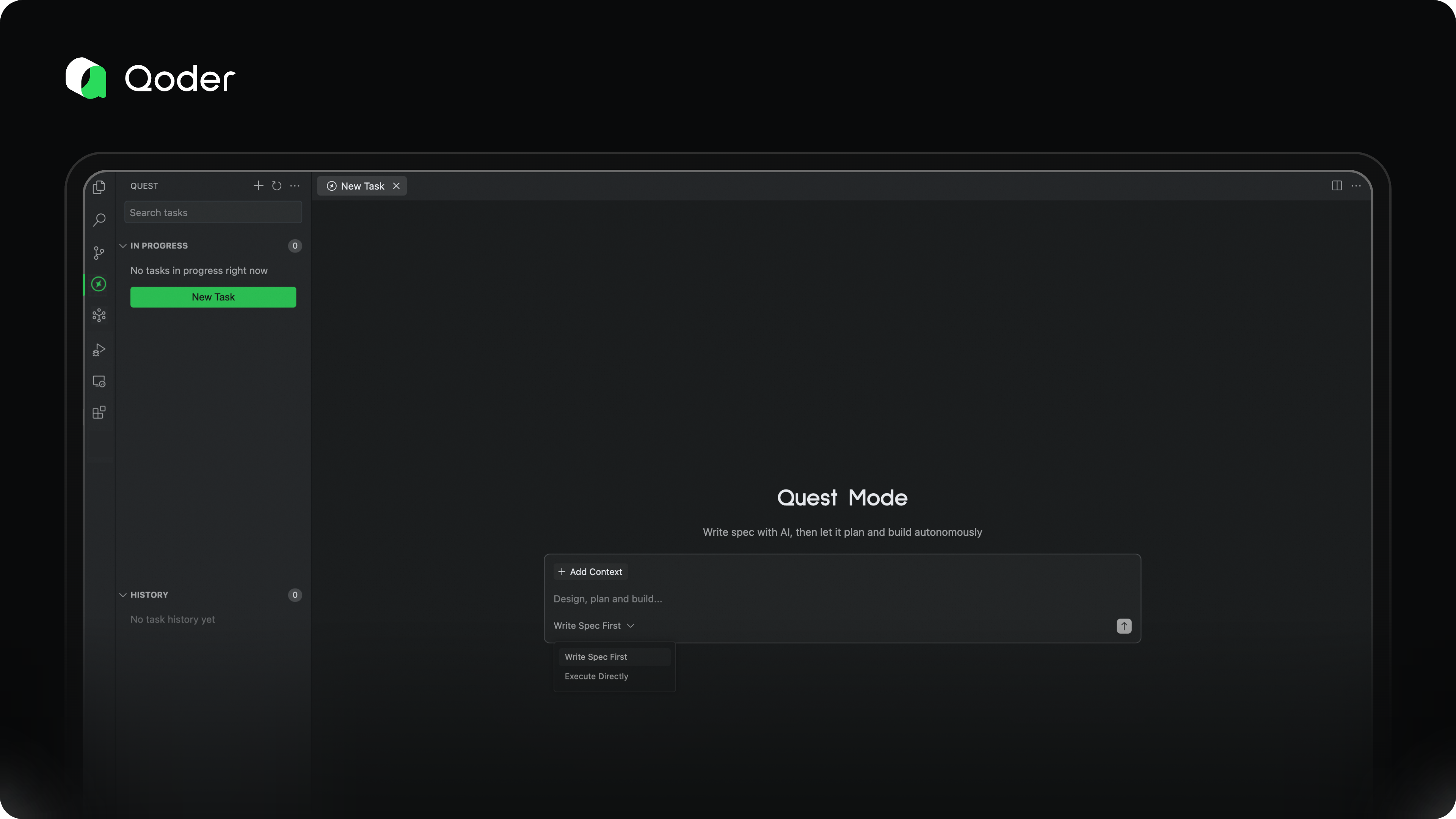
Spec First
As agents become more capable, the main bottleneck in effective AI task execution has shifted from model performance to the developer’s ability to clearly articulate requirements. As the saying goes: Garbage in, garbage out. A vague goal leads to unpredictable and unreliable results.
That’s why we recommend that developers invest time upfront to clearly define the software logic, describe change details, and establish validation criteria—laying a solid foundation for the agent to deliver accurate, high-quality outcomes.
With Qoder’s powerful architectural understanding and code retrieval capabilities, we can automatically generate a comprehensive spec document based on your intent—accurate, detailed, and ready for quick refinement. This spec becomes the single source of truth for alignment between you and the AI.
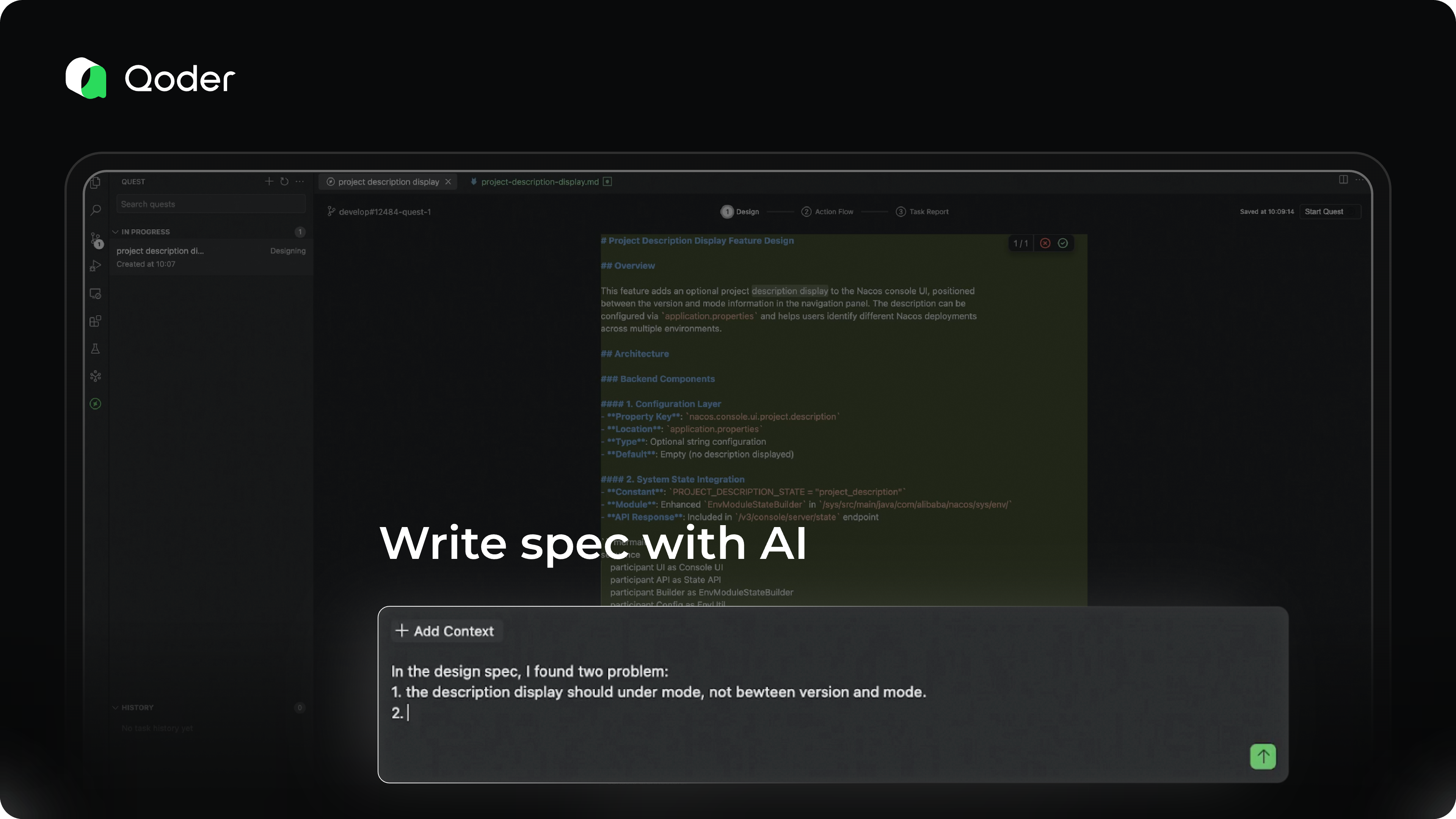
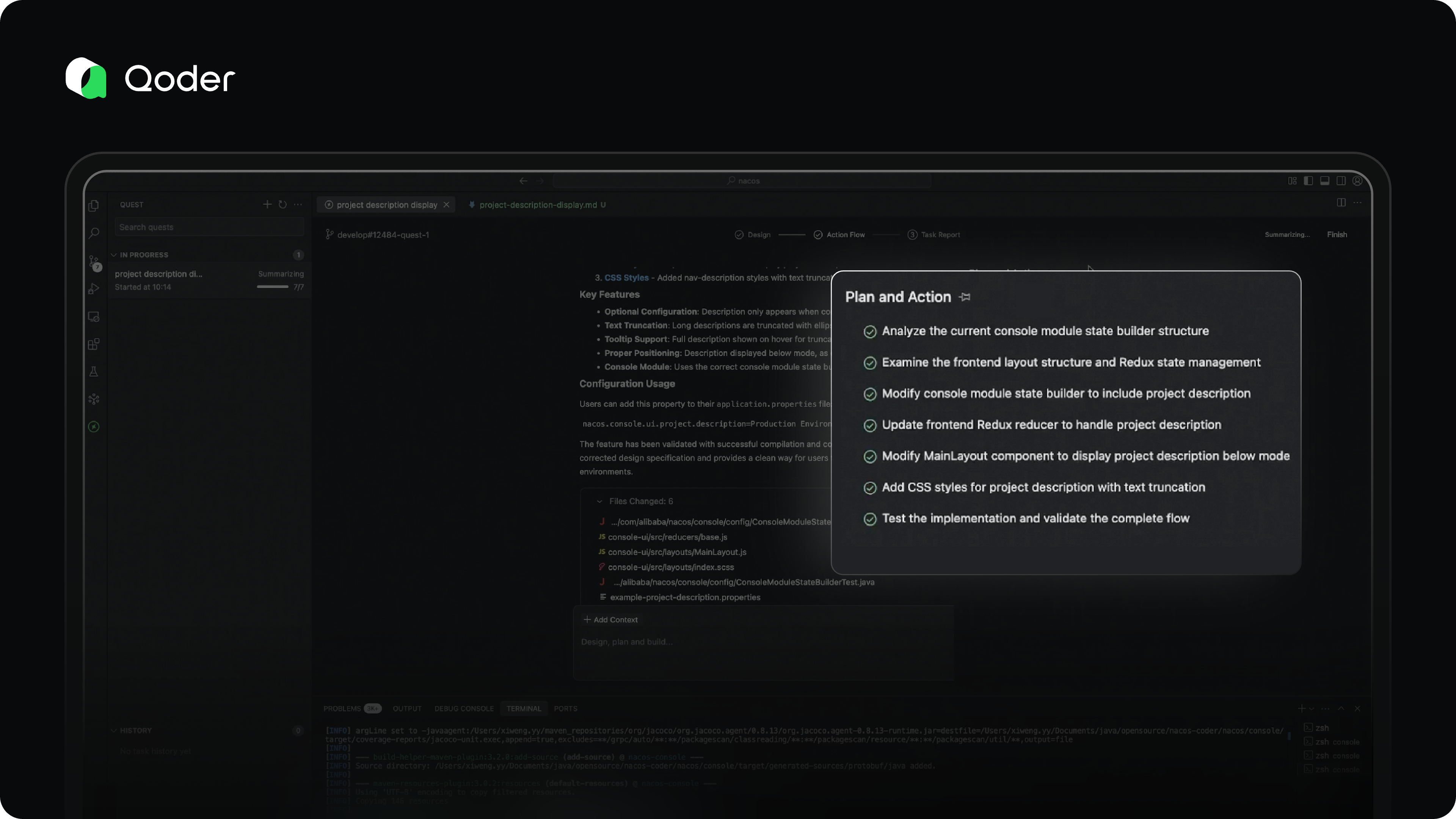
Action Flow
Once the spec is finalized, it's time to let the agent run.
You can monitor its progress through the Action Flow dashboard, which visualizes the agent’s planning and execution steps. In most cases, no active supervision is needed. If the agent encounters ambiguity or a roadblock, it will proactively send an Action Required notification. Otherwise, silence means everything is on track.
Our vision for Action Flow is to enable developers to understand the agent’s progress in under 10 seconds—what it has done, what challenges it faced, and how they were resolved—so you can quickly decide the next steps, all at a glance.
Task Report
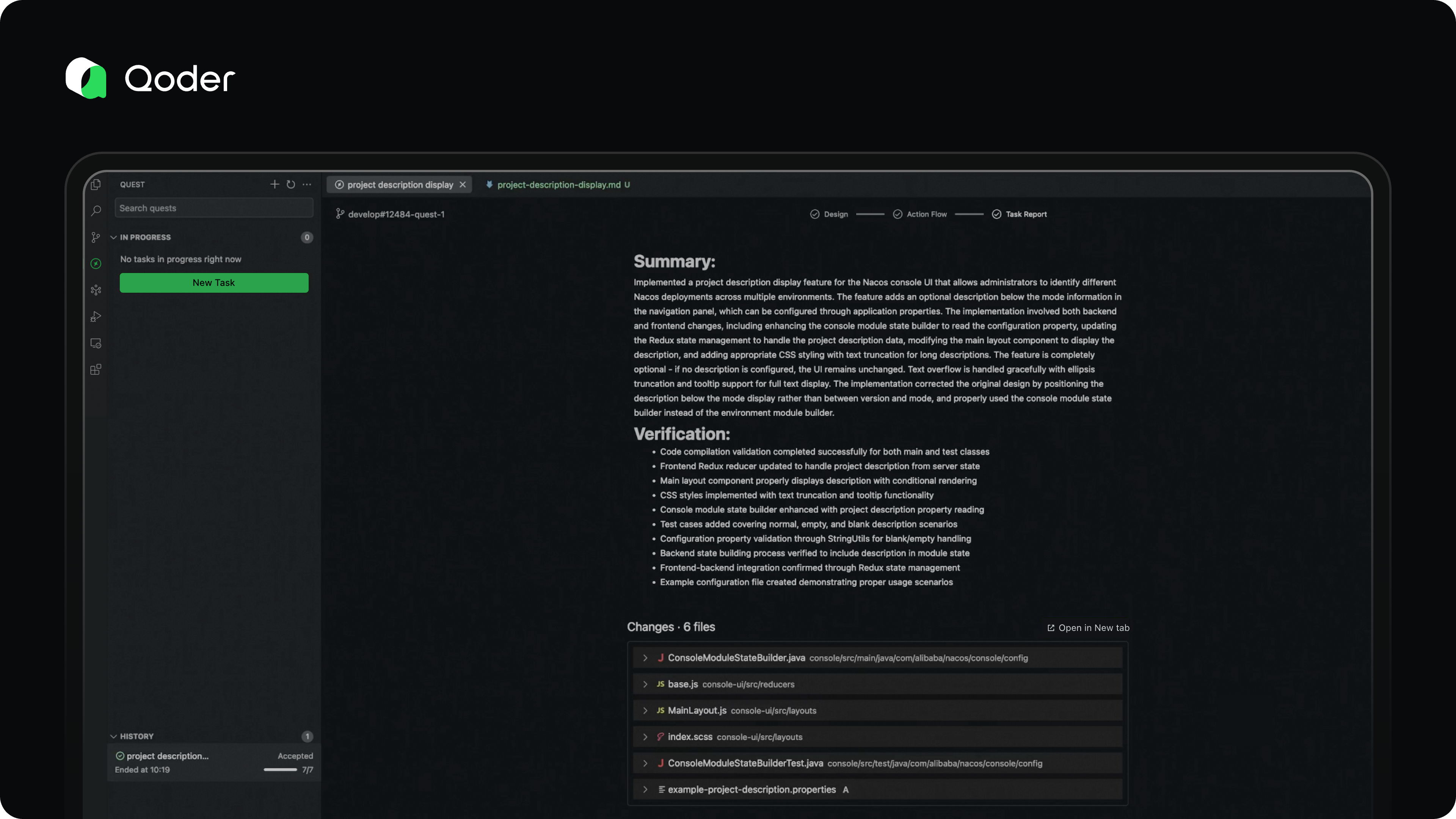
For long-running coding tasks, reviewing dozens or hundreds of code changes can be overwhelming. That’s where comprehensive validation becomes essential.
In Quest Mode, the agent doesn’t just generate code—it validates its own work, iteratively fixes issues, and produces a detailed Task Report for the developer.
This report includes:
-
An overview of the completed coding task
-
Validation steps and results
-
A clear list of code changes
The Task Report helps developers quickly assess the reliability and correctness of the output, enabling confident, efficient decision-making.
What’s Next
We’re continuing to refine Spec-Driven Development as a breakthrough approach to real-world programming efficiency. Specs are the key to ensuring that agent-generated code meets expectations.
Our long-term vision is to delegate programming tasks to autonomous agents that work asynchronously—delivering 10x or greater productivity gains.
Going forward, we’ll focus on:
-
Improving the speed and quality of collaborative spec creation between developers and AI
-
Enabling cloud-based, always-on agent execution, so your AI assistant is available anytime, anywhere
Welcome to the future of software development—where you think deeper, and let AI build better.
Stop feeding your model every tool definition
desc: How we cut 10% of Quest's context cost by not showing the model tools it doesn't need
category: Technology
img: https://img.alicdn.com/imgextra/i3/O1CN01XjwNoT26FyIKVEFRP_!!6000000007633-2-tps-1712-1152.png
time: February 25, 2026 · 5min read
Quest 1.0 is Qoder's autonomous coding agent. It takes a task description, plans a solution, writes the code, and runs it. Users can extend Quest with Skills (specialized knowledge modules loaded on demand), and this post is about an optimization we made to how Skills and MCP tools get loaded into context.
The trigger
Shortly after launching Quest 1.0, a user reported that a task burned through a large amount of credits without delivering satisfactory results.
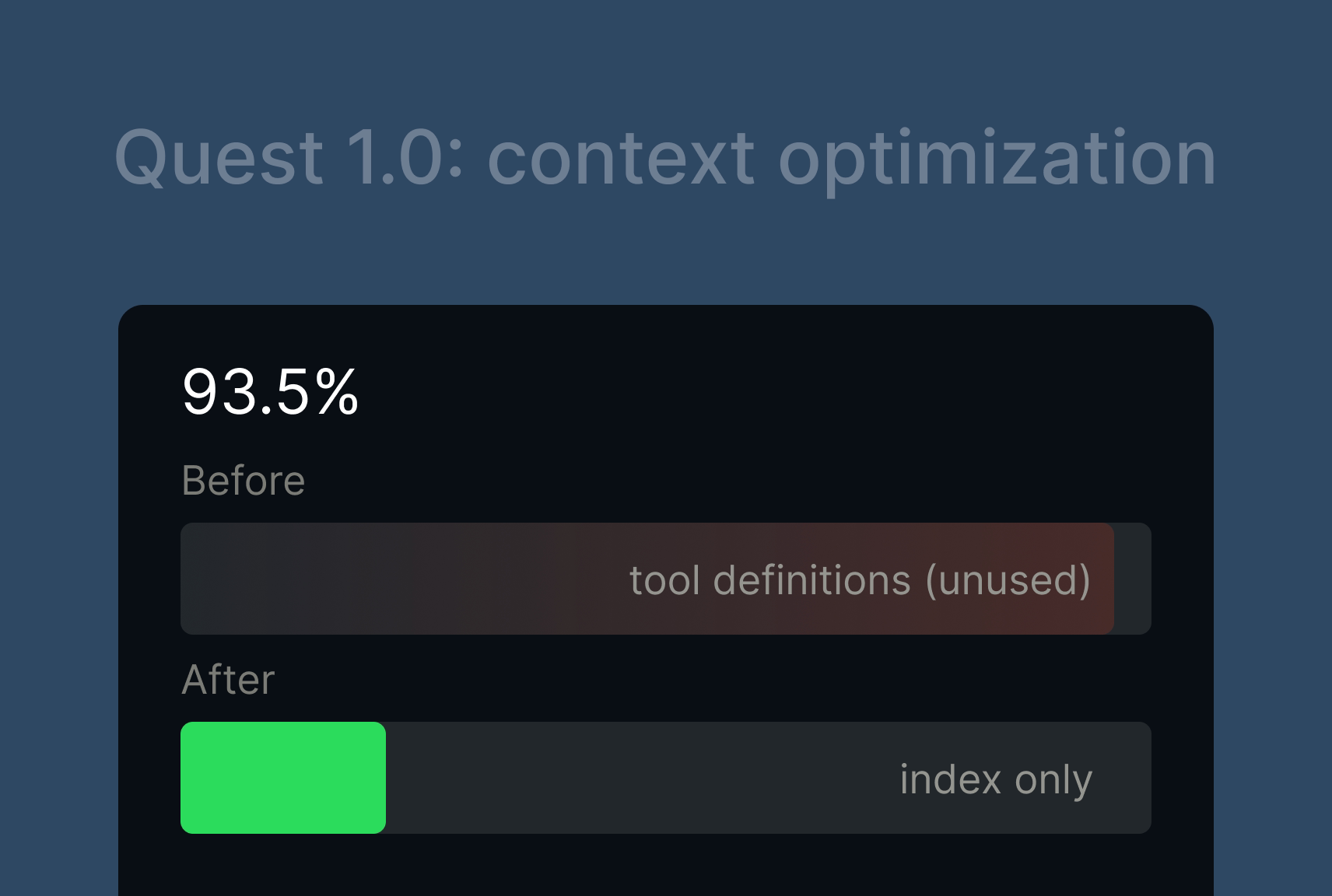
We pulled the token distribution data from that conversation. Out of 120K input tokens, 93.5% were tool definitions. None of those tools were called even once during the entire task.
This was an extreme case. The user had configured multiple MCP Servers loaded with tools. But it exposed a broader problem: context was stuffed with "just in case" definitions that rarely got used.
One of us configured playwright-mcp for frontend automation testing. After the tests were done, it sat there unused. Its tool definitions kept showing up in every subsequent conversation's context, and nobody noticed for weeks.
We ran a controlled experiment: same task, with two MCP Servers mounted (but never actually used during the task) vs. without. The unused tools alone inflated credits consumption by over 10%. The reason: just two MCP Servers contributed nearly a hundred tool definitions, consuming close to 2,000 tokens.
An internal team survey confirmed the pattern: 80% of colleagues had at least one MCP Server configured, but actual usage frequency was under 10%.
The problem was clear: how do you reduce MCP tools' context footprint without removing them entirely?
Finding inspiration in Skills optimization
Before tackling MCP, we had already hit a similar wall with another feature: Skills.
Quest's Skills feature lets users define specialized knowledge and workflows that an Agent can load on demand. But users reported that Skills' automatic invocation rate was disappointing, often requiring a manual /skills command to trigger.
We tested in an environment with 28 Skills: the model's autonomous invocation rate was under 50%.
Why was invocation rate low?
A model invoking a Skill needs to complete three steps:
- Understanding what capability the current task requires (intent recognition)
- Finding the right Skill in the known Skills list (capability matching)
- Determining when to load it and how to use it (timing)
Steps 1 and 3 depend on the model's reasoning ability and will naturally improve with model upgrades. The bottleneck was step 2: how does the model know which Skills are available?
The most straightforward approach was putting all Skills' full definitions into the system prompt. It worked, but the cost was context bloat: full descriptions for 28 Skills easily consumed thousands of tokens, while a single task typically only needed 1-2 of them.
Skill routing index
Our approach: place a lightweight Skills index in the System Reminder instead of full definitions.
The index contains only each Skill's name and a one-line description, totaling a few hundred tokens. The model uses this index for intent matching. If it determines a Skill is needed, it locates and loads the full content through the index.
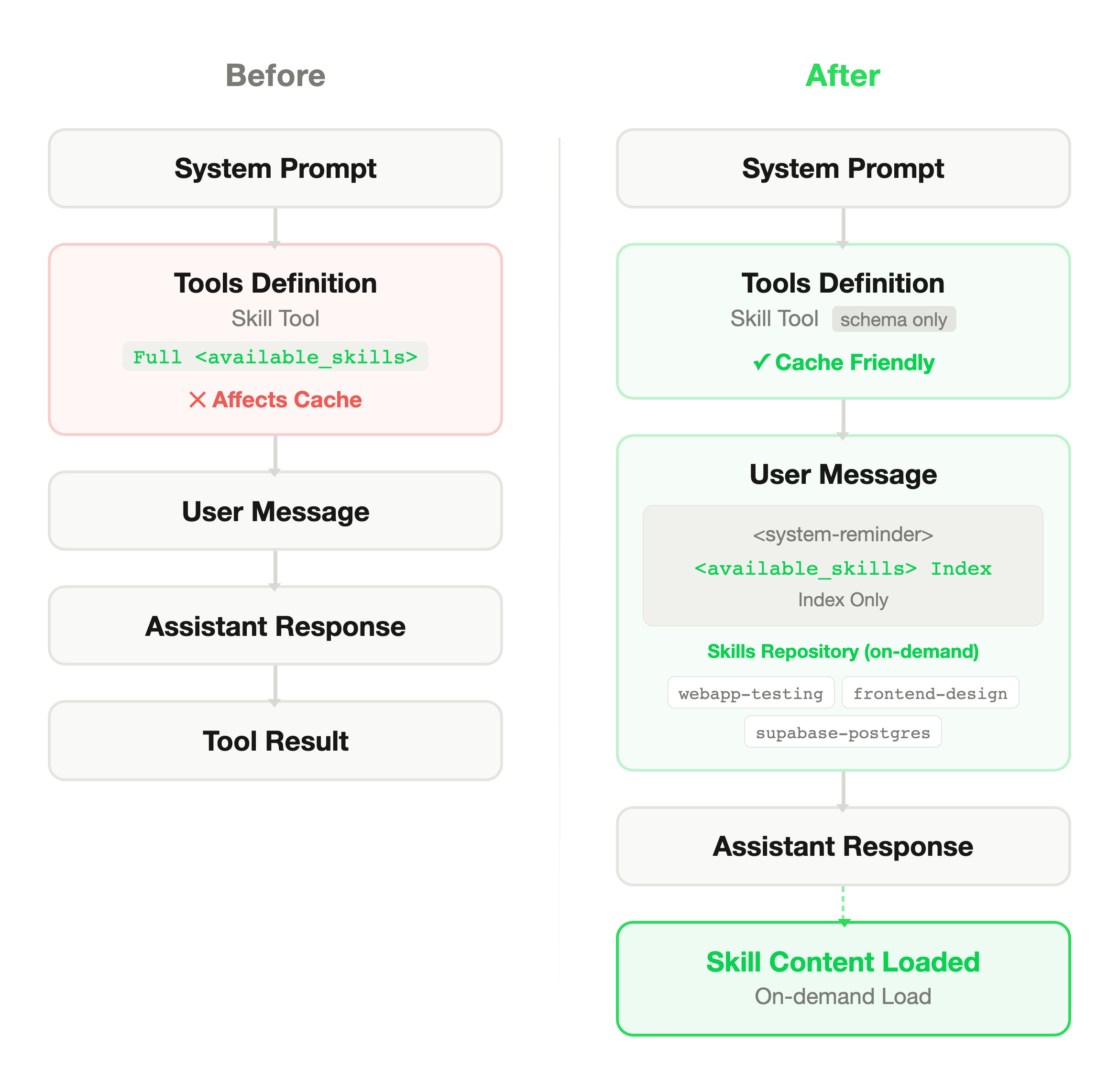
The design had three constraints. The index had to be lightweight (a new context burden would defeat the point). One-line descriptions had to be accurate enough for correct matching. And the injection mechanism had to preserve Prompt Cache hit rates, which meant leaving the Tools Definition structure unchanged and injecting dynamically via System Reminder instead.
This assumes the model is smart enough to judge whether it needs a Skill without seeing the full definition. Tell it "there's a tool called X that does Y," and it can decide whether to load it at the right moment.
Results
Skill invocation rate went from under 50% to above 90%. Total token consumption dropped by roughly 12%.
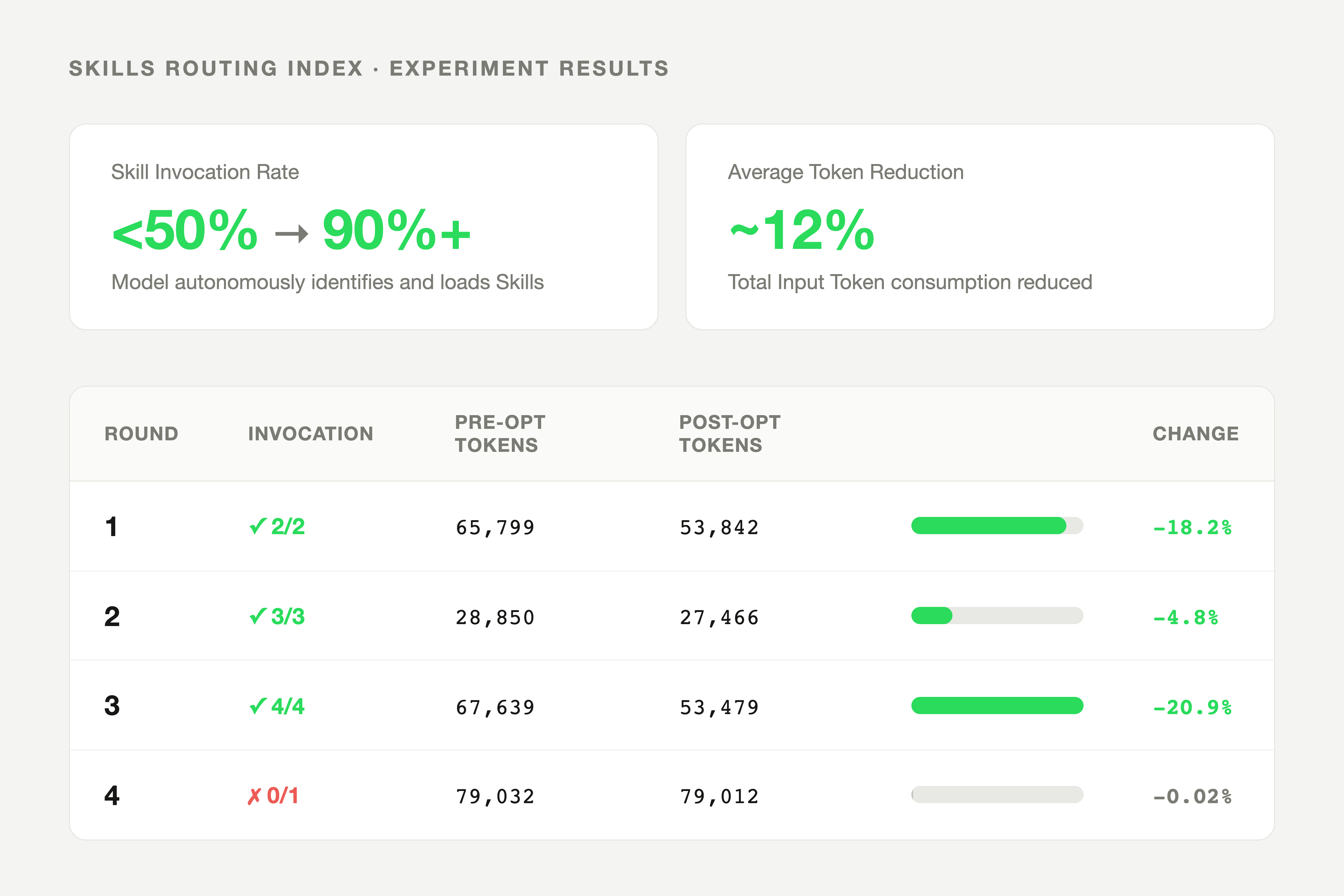
| Round | Invoked / Should Invoke | Pre-optimization Input Tokens | Post-optimization Input Tokens | Reduction |
|---|---|---|---|---|
| 1 | 2/2 | 65,799 | 53,842 | 18.2% |
| 2 | 3/3 | 28,850 | 27,466 | 4.8% |
| 3 | 4/4 | 67,639 | 53,479 | 20.9% |
| 4 | 0/1 | 79,032 | 79,012 | 0.02% |
Round 4's failure is worth noting: the Skill the task required had low similarity to its index description, so the model failed to identify it. Index quality turned out to matter more than we expected. Get the one-line description wrong and on-demand loading never triggers.
Extending to MCP: dynamic loading
The Skills experience validated a pattern: a lightweight index plus on-demand loading can compress context while preserving functionality.
MCP tools face the same problem. Could we apply the same approach?
Technically yes, but MCP adds a layer of complexity. Skills are essentially text instructions with forgiving formatting. MCP tools require precise JSON Schema for correct invocation: parameter names, types, nested structures. A missing field or type mismatch causes the call to fail. So MCP's dynamic loading demands higher "injection precision."

Our design uses two phases.
Phase 1 is discovery: the System Reminder shows only MCP tool summary indexes (name + one-line description), without full Schema. This mirrors the Skills approach.
Phase 2 is injection: when the model determines it needs a specific MCP tool, it calls a meta-tool called LoadMcpTool, which dynamically injects that tool's full JSON Schema into the current context. After injection, the model can invoke the tool through the standard flow.
LoadMcpTool is a lightweight tool whose Schema is always present in the context (consuming only a few dozen tokens). It is the gateway: the model uses it to "pull" other tools' full definitions.
The result: the initial context contains only summary indexes, full Schema is injected when needed without simplification, and the model always invokes tools from complete definitions.
Associative preloading
A practical issue: MCP Servers typically contain a group of related tools. For example, browser-use Server includes click, fill, navigate, screenshot, and over a dozen other tools. If a user's task involves browser operations, the model likely needs several of them. Loading each individually via LoadMcpTool adds multi-round call overhead.
Borrowing from spatial locality in CPU caches, we added an optimization: when the model loads any tool from a Server, it can optionally preload other high-frequency tools from that same Server.
In practice, a browser task that would have triggered several separate LoadMcpTool calls now typically triggers one.
Test results
Test environment: 67 MCP tools. Task: build a website and test it with browser tools.
Initial context fell by 32%, overall cost by 10.4%, and tool call success rate stayed at 100%.
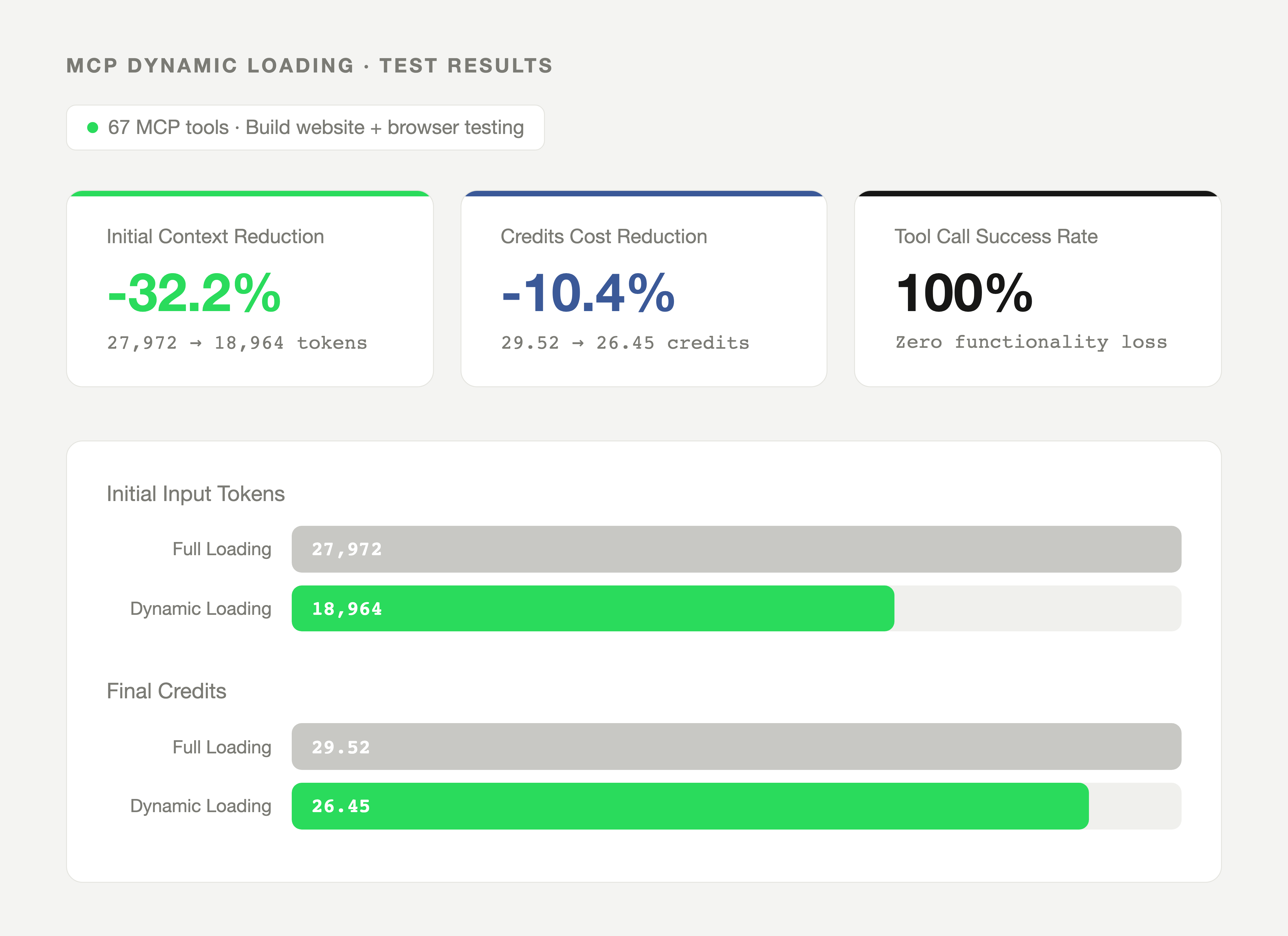
| Metric | Full Loading | Dynamic Loading | Change |
|---|---|---|---|
| Initial Input Tokens | 27,972 | 18,964 | 32.2% |
| Final Credits Consumed | 29.52 | 26.45 | 10.4% |
| MCP Tool Call Success Rate | 100% | 100% | No change |
In retrospect: this is progressive disclosure
After building both optimizations, we stepped back and noticed they were the same solution.
In 1984, IBM researcher John Carroll described Progressive Disclosure: don't show users everything at once. Expose common features first; reveal the rest when they need it. Word's collapsible menus, Notion's / command, iOS's nested settings are all this principle applied to UI.
We'd done the same thing to a context window. A lightweight index up front so the model knows what's available. Full definitions loaded only when needed. The "user" is an AI model and the "interface" is context, but the design problem is identical: feature richness versus cognitive load.
Carroll was solving this in 1984 with command menus. We were solving it forty years later with JSON Schema.
What this means for Qoder Quest users
If you're on Qoder Quest 1.0, this is already live and requires no settings changes. The biggest difference will be visible if you have MCP Servers mounted: tool definitions that ate context every turn now only load when needed. Skills also invoke automatically, so you no longer need to trigger them manually with /skills.
Inspiration for agent builders
These patterns apply beyond Quest. If you're building AI agents:
- Run a token distribution an...
QoderWork Plugins
desc: Package your team's expertise, tool integrations, and reference materials into a complete AI work suite — install once, share across the organization.
category: Product
img: https://img.alicdn.com/imgextra/i1/O1CN01Miyl7g1yzIZuFN7xo_!!6000000006649-2-tps-1712-1152.png
time: Apr 25, 2026 · 5min read
Today, we are introducing QoderWork Plugins.
A Plugin packages Skills, Connectors, and reference materials into a complete work suite, enabling AI to perform tasks according to the professional methodology of a specific role. Installing a Plugin gives AI a full set of role-level working capabilities — from domain expertise and tool access to execution workflows and output standards.
The first set of official Plugins is now available, covering corporate legal, equity research, investment banking, consulting, finance, product management, and more. More importantly, any user can create a custom Plugin based on their own team's knowledge system and distribute it across the organization with one click.
What Problem Plugins Solve
The general capabilities of large language models are no longer in question — passing the bar exam, CFA Level III, or medical licensing boards is well-established. Yet in real work environments, AI adoption remains low. In most enterprises, AI is still confined to translation, meeting summaries, and document polishing.
The root cause: generic AI possesses none of the proprietary working knowledge that defines any specific role.
The 28-item risk control checklist a legal team relies on for contract review, the due diligence framework an investment banking team has refined over a decade, the 128-point verification process a finance department follows for monthly close — this knowledge is highly specific, absent from any public resource, and varies from one organization to the next. Without it, AI can only produce generalized responses that lack practical value.
Plugins are designed to systematically inject this proprietary knowledge into AI.
What a Plugin Contains
A Plugin comprises the following core components:
- Skills — Define the role's professional capabilities and working methodology. Examples include contract review, compliance checks, and equity research analysis, each with built-in execution processes and judgment criteria.
- Connectors — Configure the external tools and data sources AI can access. Through the MCP protocol, Connectors integrate contract management systems, legal databases, financial terminals, enterprise messaging platforms, and other business systems — extending AI's reach from conversation into the actual work environment.
- Reference materials — SOP documents, work templates, exemplary past outputs, checklists, and internal policies. These files provide the domain knowledge that grounds Skills, ensuring AI output aligns with the team's actual standards rather than generic responses.
Additionally, plugin.json defines the Plugin's metadata (name, version, description, target role). The entire Plugin is packaged in a standardized format, supporting cross-team installation and management.
Official Plugins: Structured Industry References
The initial set of official Plugins is not designed as "install-and-go" standard products. They are positioned as industry-level structural references — demonstrating how a role's work can be systematically decomposed and encoded into an AI-executable suite.
This design choice reflects a fundamental judgment: the specificity of professional work means no truly universal solution exists. Two teams in the same industry often work quite differently, and attempting to cover all scenarios with a single generic package is neither realistic nor the goal of this system.
Official Plugins serve as starting points. Users can modify, extend, or entirely recreate them to match their own team's working practices.
Building on that foundation, domain experts within each department create Plugins that truly fit their own work systems — this is the core design intent of the mechanism.
Creating a Custom Plugin
The Plugin marketplace includes a "Create Plugin" entry point. The entire process is guided by QoderWork and requires no code:
- Define role and core scenarios — specify the role the Plugin serves, and plan the required Skill set
- Provide reference materials — upload the team's SOPs, work templates, historical examples, checklists, and internal standards
- Configure tool integrations — select the Connectors the role uses daily (e.g., contract management system, legal databases, CRM, enterprise messaging)
- Generate and distribute — QoderWork integrates these inputs into a complete Plugin; once packaged, it can be installed across the entire team with one click
This mechanism enables the people who understand the work best — rather than technical teams — to directly define how AI operates. A senior practitioner's methodology, accumulated over years, can be packaged into a Plugin and instantly shared across the organization. A new team member installing it on day one receives the same AI working capability as the rest of the team.
Use Skills to validate individual methodology during exploration. Once proven, package into a Plugin for team-wide distribution. This is the complete path from personal practice to organizational capability.
Getting Started
Open the Extensions panel in QoderWork's sidebar and enter the Plugin marketplace.
Install an official Plugin to see how role-specific workflows are structured, and invoke individual Skills via / commands in conversation. Or go directly to "Create Plugin" — package your team's expertise, tool integrations, and working standards into an AI-executable work suite, distributable to the entire team with one click.
QoderWake: Your always-on AI Employee
desc: To add a type of AI employee to organizations that is production-ready, secure, controllable, and continuously evolving.
category: Product
img: https://img.alicdn.com/imgextra/i3/O1CN01LyGkWI1e2PKuC4OWH_!!6000000003813-2-tps-1712-1152.png
time: April 30, 2026 · 3min read
Today, a new member joins the Qoder family: QoderWake. It is now officially available for invitational preview.
AI lets one person handle the end-to-end work that previously required a small team. "Super individuals" have shifted from a topic to an executable operational reality. Cases of one-person armies are increasing. At the organization level, small closed-loop teams replace large departments. AI employees join teams. The "communication is execution" collaboration pattern is creating a group of "super organizations". Both trends point to the same gap. Organizations need schedulable AI employees with borders. These employees must work with humans long-term to connect individual capabilities with organization collaboration.
What QoderWake aims to do is fill this gap: to add a type of AI employee to organizations that is production-ready, secure, controllable, and continuously evolving.
QoderWake is your next AI employees. Always Awake. Always Working.
A QoderWake digital employee consists of five layers. These are identity, memory, skills, division of labor, and permission red lines. Identity defines who the employee is. Memory saves long-term context. Skills determine which tools the employee can invoke. Division of labor determines how to split complex Jobs. Permission red lines dictate which tasks require your approval.
The relationship between you and the employee is employer-employee. You name the employee, assign the role, and draw red lines. If you change devices, LLM engines, or workstations, the employee remains the same and follows you. A plain text personality profile acts as the ID card. You can view, Edit, and manage this profile using Git. After the subscription period ends, the training Results do not disappear.
The underlying design separates the employee from the workstation. The employee saves the identity, memory, skills, and permissions. The workstation provides the Run environment. This environment can be a local computer or a cloud sandbox. If the environment changes or restarts, the employee continues the previous work. During the invitational preview, each digital employee stays on your device by default. You decide whether to upload the Code or memory to the cloud.
The ID key, memory summary, Task Queue, and each report remain. You can view, manage, and take over them at any time.
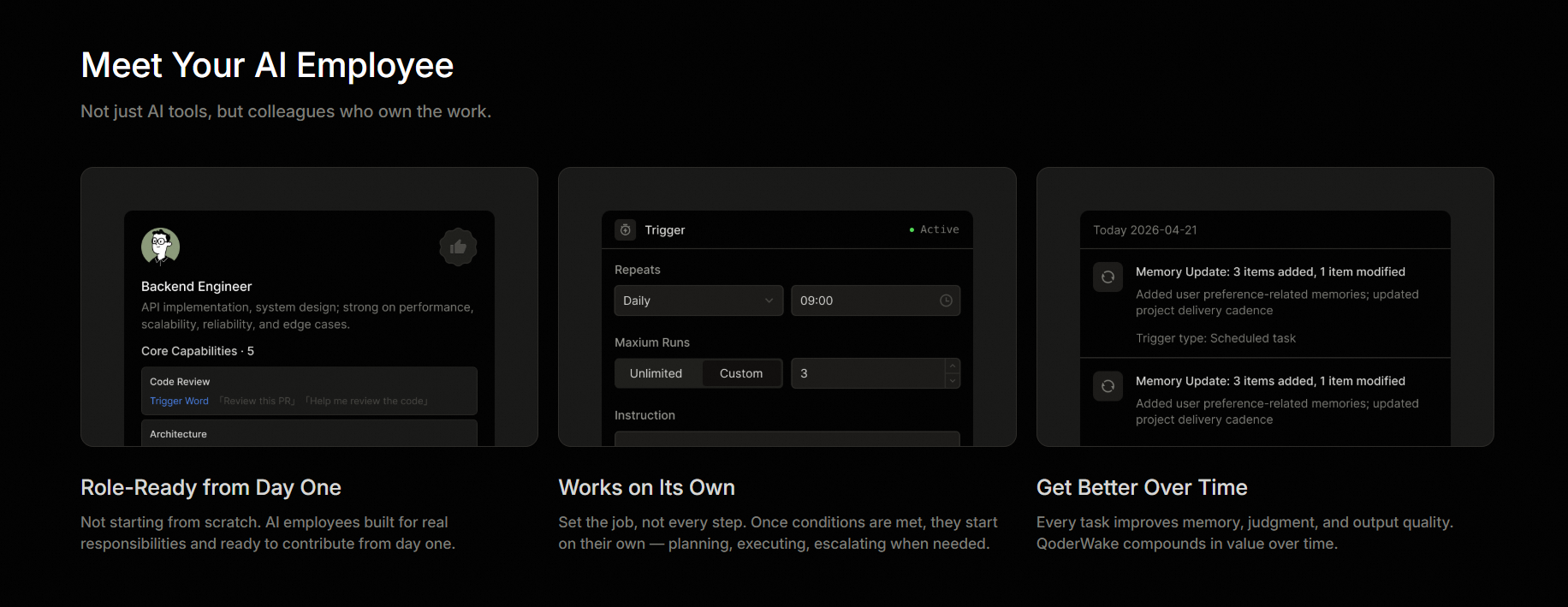
Take digital programmers as an example. This job is naturally suited as a training sample. The Job borders are clear. The Results are verifiable. The tasks occur continuously. They directly Impact delivery efficiency, System stability, and engineering quality. After onboarding, this employee handles four classes of work first. When the Code has Updates, the employee checks the impact scope first. Then, the employee prepares a Change brief for you. The employee connects the scattered Change information for you. When an error occurs, the employee performs a Diagnosis first. The employee prepares an initial Diagnosis report. This report includes what the error is, why it happened, and how to fix it. When an alerting goes off, the employee performs triage first. The employee determines the critical level, possible root causes, and whether to escalate the issue to humans. When the backlog piles up, the employee organizes it first. The employee sorts the Priorities, impact scopes, and suggested actions. The employee signs each output to help you trace back.
Here is a more complete example. A service reports an error at night. The employee first checks recent commits, reviews the alerting context, and organizes possible causes. Then, the employee provides an initial Diagnosis report and a fix path. If it is a configuration issue within the border, the employee submits fix suggestions based on your rules. If the employee encounters red lines such as mainline Changes, external Notifications, or production Data, the employee stops and asks for instructions. You do not need to be present during the entire procedure. Simply spend a few minutes in the morning reviewing the report and deciding the next step.
Harness engineering challenges for running QoderWake 24/7
QoderWake Harness Engineering implements industry-consensus technical capabilities. These include decoupling orchestration, Job loops, context engineering, feedback verification, Status persistence, crash recovery, and full guardrails. However, this is still not enough for a product that runs 24/7, such as QoderWake.
The real challenge of running 24/7 is capability rot. For example, outdated memory pollutes the context. Skills become outdated or conflict with each other. Learning more causes more confusion and becomes more dangerous. Many single-point self-evolution capabilities in the industry, such as memory Management, skill libraries, trajectory Analysis, and session Insights, remain at the level of records and local accumulation. QoderWake must build a systematic path from execution experience to capability growth while preventing rot.
QoderWake Harness Engineering focuses on solving three challenges based on industry-consensus Harness Engineering capabilities. How to ensure security and controllability at the architecture layer? How to ensure production readiness at the execution layer? How to achieve continuous evolution at the capability layer?
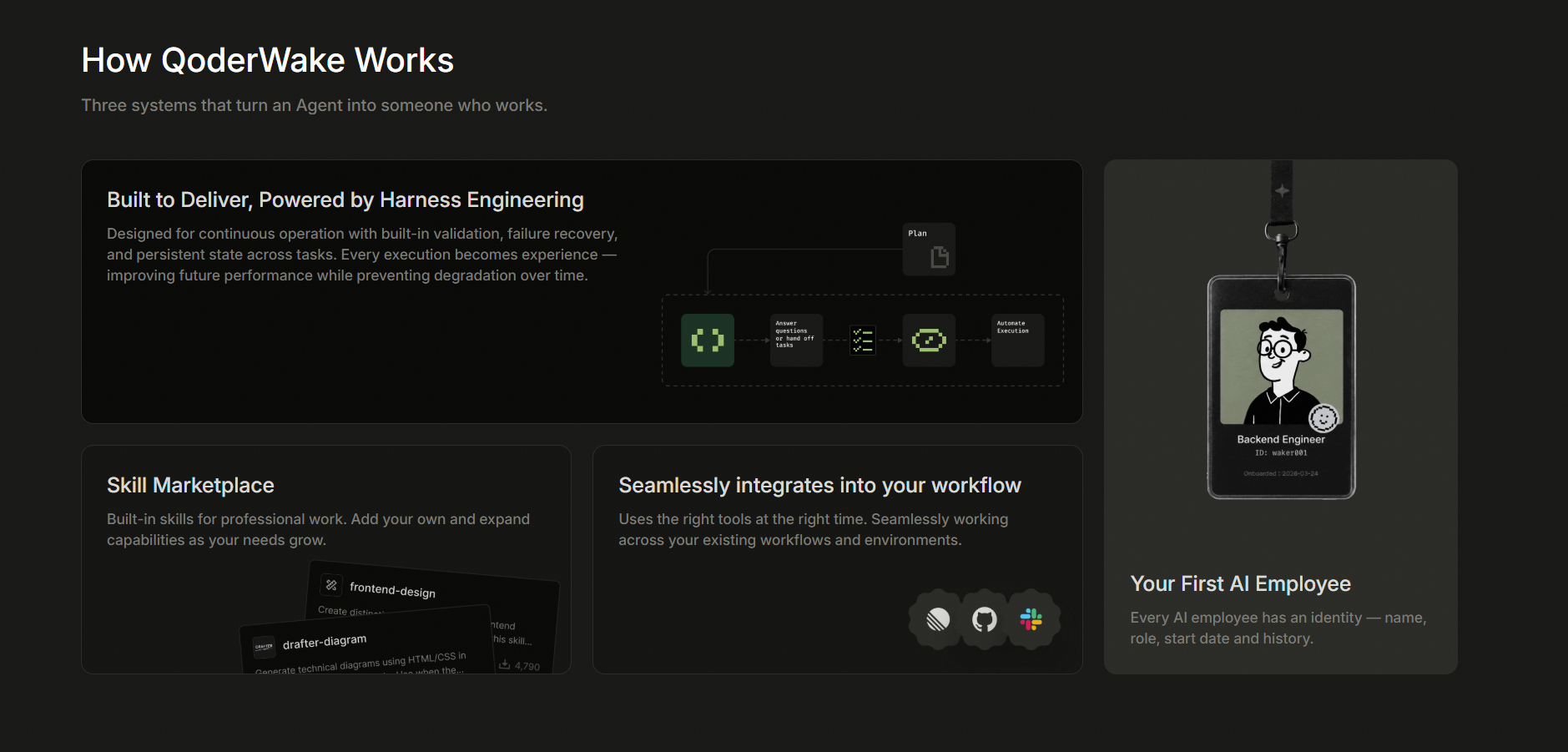
Harness-First architecture: secure and controllable
Separation of duties between certainty and probability. At the decision-making layer, the Orchestrator uses a deterministic flow orchestration mechanism. This ensures that long-term Jobs execute reliably and stably. The model is mainly responsible for intention recognition and inferring. This achieves Brain-Hands-Session decoupling.
Cross-Job persistence of two-layer feedback and failed constraints. At the execute layer, the executor generates and instantly authenticates the results. An independent authenticator (Verifier) reviews the overall Result. If authentication is failed, it triggers a Redo (REWORK). The reason for the failed Result is saved as knowledge. This knowledge serves as priori input for Jobs of the same class in the future.
Session acts as the Unique Status source independent of all widgets. At the reliability layer, all execute management events and Status are stored in the Session layer. If any widget crashes, it can be fully rebuilt based on the Session Status information. This recovers the sequence idempotence.
Execute as experience: active for production
Currently, event logs for steering engineering in the industry are mainly used to recover and audit. QoderWake uses knowledge accumulation and layered memory to treat each execute Result as input for experience accumulation. Each execute operation accumulates production-grade experience.
Distill experience from execute operations. The knowledge engine distills reusable domain experience from specific task execution. For example, consider a failed Code review Job on Day 10. By combining it with previous execute Data, the engine can distill the experience that "a payment module Change must maintain the transaction structure." This experience is not explicitly mentioned in an event-at-a-time.
Automatic Backflow of execute experience. The digital employee experience on Day 1 is the initial baseline. On Day 90, it becomes expert-level experience adapted to individuals and enterprises in depth. Time accumulation becomes part of the product capabilities.
Experience to capability: continuous evolution
Experience accumulation alone is Not Equal To capability growth. Remembering more does not mean doing better. Industry steering engineering optimization mostly focuses on the success rate of a single Job. QoderWake emphasizes a cross-Job, long-term Experience-to-Capability evolution path. It uses three layers to solve "how to learn, what to learn, and how to prevent rot."
Unify multidimensional management events into learnable signals. QoderWake unifies multidimensional management events into structured learnable signals. These management events include dialogs, tool calling, memory retrieval, authentication Results, User corrections, and Redo operations. This provides a complete factual basis for subsequent Attribution and capability accumulation.
Trajectory Attribution performs Attribution based on the complete trajectory. QoderWake performs Attribution based on the complete Job trajectory. It determines whether the experience should be saved as memory, skills, policies, authenticators, or workflows. The accumulation Target is determined by complete trajectory evidence, rather than preset rules.
Anti-rot administration prevents learning confusion. The anti-rot administration (Anti-Rot Governance) mechanism of QoderWake performs monitoring, authentication, demotion, merge, and revoke administration on various long-term capabilities. Outdated memory is eliminated. Conflicting skills are merged or demoted. Invalid policies are revoked. This keeps the memory, skills, workflows, and preferences of AI employees fresh and free from rot.
Invite your AI employee to onboard
Starting today, QoderWake officially opens its invitational preview. We invite users to onboard in batches. We prioritize individuals or teams with clear work scenarios, clear work borders, and real collaboration requirements. To request to join the onboarding list, visit qoder.com/qoderwake...
In Practice: QODER CLI × HARNESS ENGINEERING — Building a 7×24 Autonomous Feedback Processing System
desc: A 7×24 unattended feedback system built on Qoder CLI, compressing root-cause analysis per issue from 30 minutes to 2.
category: Technology
img: https://img.alicdn.com/imgextra/i4/O1CN01QdHNTC1WKFqHk40BR_!!6000000002769-2-tps-1712-1152.png
time: April 24, 2026 · 3min read
Background
As the Qoder product family grows and user volume continues to climb, feedback and suggestions from users across Qoder products are increasing rapidly. However, the previous feedback handling process was entirely manual: operations staff exported Excel data from feedback channels, cleaned and categorized it, then manually entered it into the project management system. Finally, engineers analyzed logs and pinpointed issues by hand.
The pain points of this workflow are obvious — operations got trapped in repetitive work of data entry and ticket dispatch, while engineers spent at least 30 minutes on each log analysis task, and even longer for complex issues. As feedback volume grew, the human bottleneck became increasingly pronounced, with large backlogs piling up without timely response.
Our goal is clear: build a 7×24 autonomous user feedback processing system — from feedback submission to issue classification, clustering, log analysis, and even code fixes, all handled automatically by Agents, with humans only doing a final review at the last Code Review stage.
Product Design
To achieve this, we designed a new issue-processing backend with four core modules connected in a pipeline sequence:
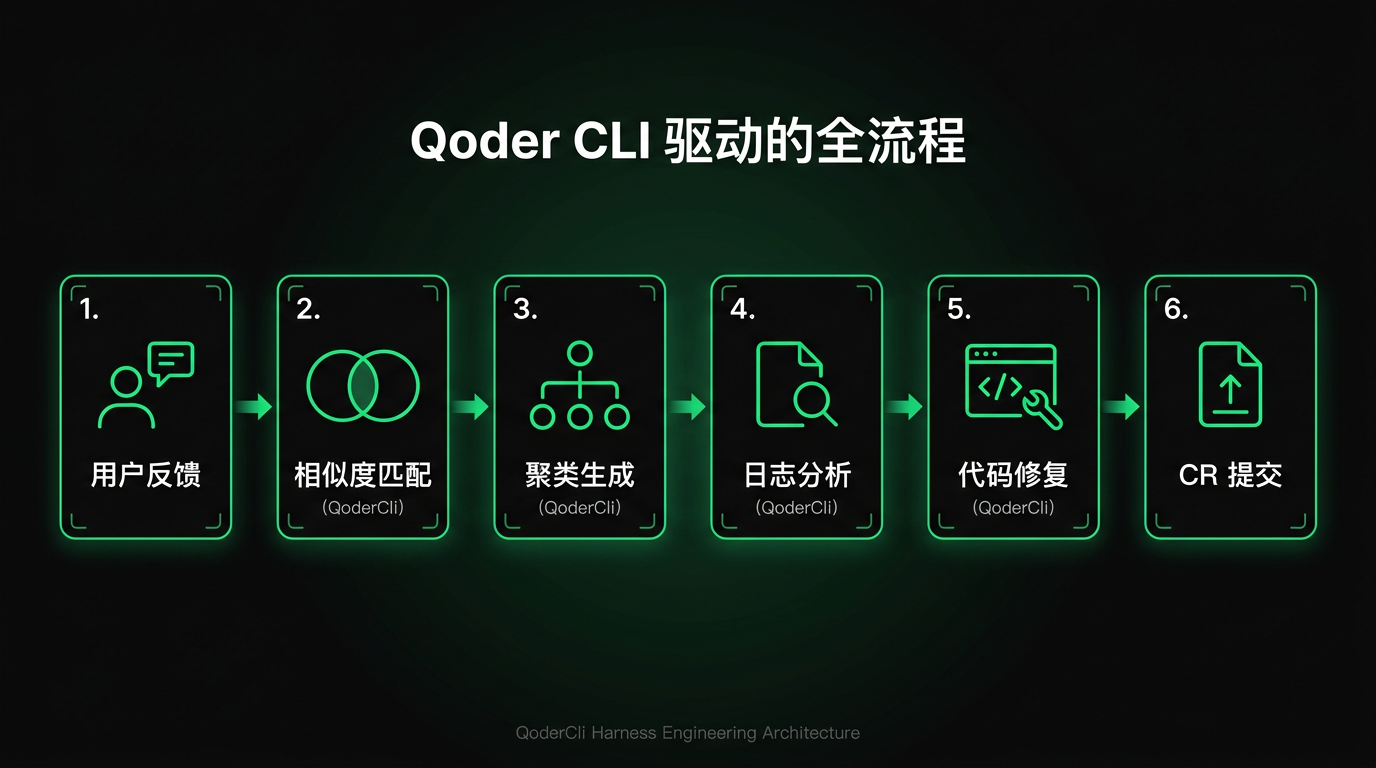
Issue Classification: After a user submits feedback, the system first filters out invalid data, classifies valid feedback into product suggestions and bug reports, and further determines the business-domain subcategory for bug reports. This step replaces the manual classification and entry work previously done by operations staff.
Issue Clustering: On top of classification, the system aggregates similar issues. This reduces interference from duplicate problems, allowing subsequent advanced analysis to focus on issues that truly need attention, rather than being drowned by N reports of the same bug.
Log Analysis: For bugs requiring deep investigation, the system automatically analyzes logs in conjunction with the codebase, extracts user operation trajectories, identifies root causes, and provides fix recommendations. This step replaces the manual log analysis previously done by engineers.
Auto Fix: For issues where the AI has high confidence in a fix, the system automatically generates fix code and creates a Code Review, with humans performing the final review.
For the boundary between human and machine collaboration, our principle is: classification, clustering, and analysis are fully delegated to Agents; code fixing is done by Agents but retains human Code Review as a quality gate. Agents handle throughput; humans ensure quality.
Technical Implementation
Why Qoder CLI
The entire AI capability layer of our system is built on Qoder CLI. The reasons for choosing CLI over direct model API calls or other Agent frameworks are core:
| Feature | Advantage |
|---|---|
| Interaction Model | Naturally Agent-friendly, atomic operations, pure text stream processing, easy for LLM parsing |
| Environment Compatibility | Unified interaction logic, Agents seamlessly migrate across platforms, local dev machines, CI/CD pipelines, and production servers |
| Process Isolation | Each invocation is an independent process, tasks do not interfere, failures or timeouts do not affect the host service |
| Observability | Execution logs, Exit Code, Stdout/Stderr are all traceable, enabling Agent backtracking and self-correction |
| Standard Protocol | Based on POSIX/Shell standards, Agents can precisely invoke CLI capabilities, pipe composition without multiple adapters |
| Rich Tooling | Built-in grep, read, web_search tools, Agents can autonomously plan invocations without extra toolchain development |
For Harness Engineering scenarios requiring 7×24 continuous operation, CLI's instant start/stop, concurrency-friendly, and process-isolation characteristics are especially critical. Direct model API calls require managing tool invocation, context windows, retry logic, and much other infrastructure code, while Qoder CLI encapsulates all of this — we only need to focus on business orchestration.
Environment Setup
Add the Qoder CLI installation script to the server-side application's Dockerfile:
RUN curl -fsSL https://qoder.com/install | bash
Then copy the Access Token from https://qoder.com/account/integrations and configure it as the environment variable QODER_PERSONAL_ACCESS_TOKEN. This allows Qoder CLI to be invoked via subprocess from the server-side code.
When invoking, pass the prompt via the -p parameter and enable headless mode without TUI interaction. Other commonly used parameters:
--yolo: Auto-confirm mode, no human interaction needed--model: Model tier selection, better models cost more--output-format=json: Structured output for program parsing, observe reasoning process--worktree: Independent workspace to avoid multi-task file conflicts--max-turns: Limit maximum turns to prevent infinite loops wasting tokens
Issue Classification
After user feedback data is submitted, Qoder CLI is first used for preliminary issue classification. In this single-turn task, Qoder CLI performs:
- Filter out invalid data without specific feedback information
- Classify remaining issues into product suggestions and bug reports
- Determine whether bug reports are valid defects
- Further classify valid defects into business-domain subcategories
This task does not require high model capability or deep reasoning; --model with Effective tier is sufficient, saving significant cost.
Issue Clustering
After parsing Qoder CLI's structured output, we obtain issue classifications. Within each category dimension, a similarity matching and clustering task is performed.
Clustering uses Qoder CLI for LLM semantic understanding rather than traditional text similarity algorithms. The reason: the same issue may be described in completely different ways, and user screenshots must also be considered — pure text matching cannot handle this.
In this task, we leverage Qoder CLI's Auto model tier multimodal capability to comprehensively analyze screenshots, user descriptions, and client environment information, generating clustering metadata for matching against the active issue database, and passing this data to another Qoder CLI subprocess for clustering.
To ensure clustering quality, the context length fed to the large model must be controlled within a certain range to prevent memory and attention degradation. Therefore, we set a dynamic time window to retire old clustering issues, using issue freshness combined with a time-decay coefficient to improve correct clustering hit rate.
Since the Auto model tier's capability range is limited, its clustering output requires further dynamic tuning. We have Qoder CLI output issue similarity data, allowing dynamic threshold adjustment to tune aggregation effects in practice. Going further, we can use an advanced model to set up an "inspector" within the Harness Engineering system to sample and review aggregation results, providing adjustment direction recommendations for the similarity threshold based on quality-check outcomes.
Log Analysis and Root Cause Identification
After issue classification and clustering, the system enters a deeper technical analysis phase. The goal of this task is to analyze logs in conjunction with the codebase, extract user operation trajectories, and identify root causes.
Here, Qoder CLI's Performance model tier is used, fully leveraging its Agent autonomy and rich tool invocation capabilities. Codebases and logs are typically very large, and reading everything with the read tool would degrade results. Qoder CLI intelligently uses the grep tool to efficiently search relevant content based on issue descriptions, and even autonomously plans web_search tool queries for similar issues on VS Code without prompting.
Before the task concludes, we require Qoder CLI to perform a retrospective review: could fewer tool invocations have found the root cause? Which steps in this operation were ineffective or avoidable? What lessons learned can be summarized to prevent the same mistakes next time?
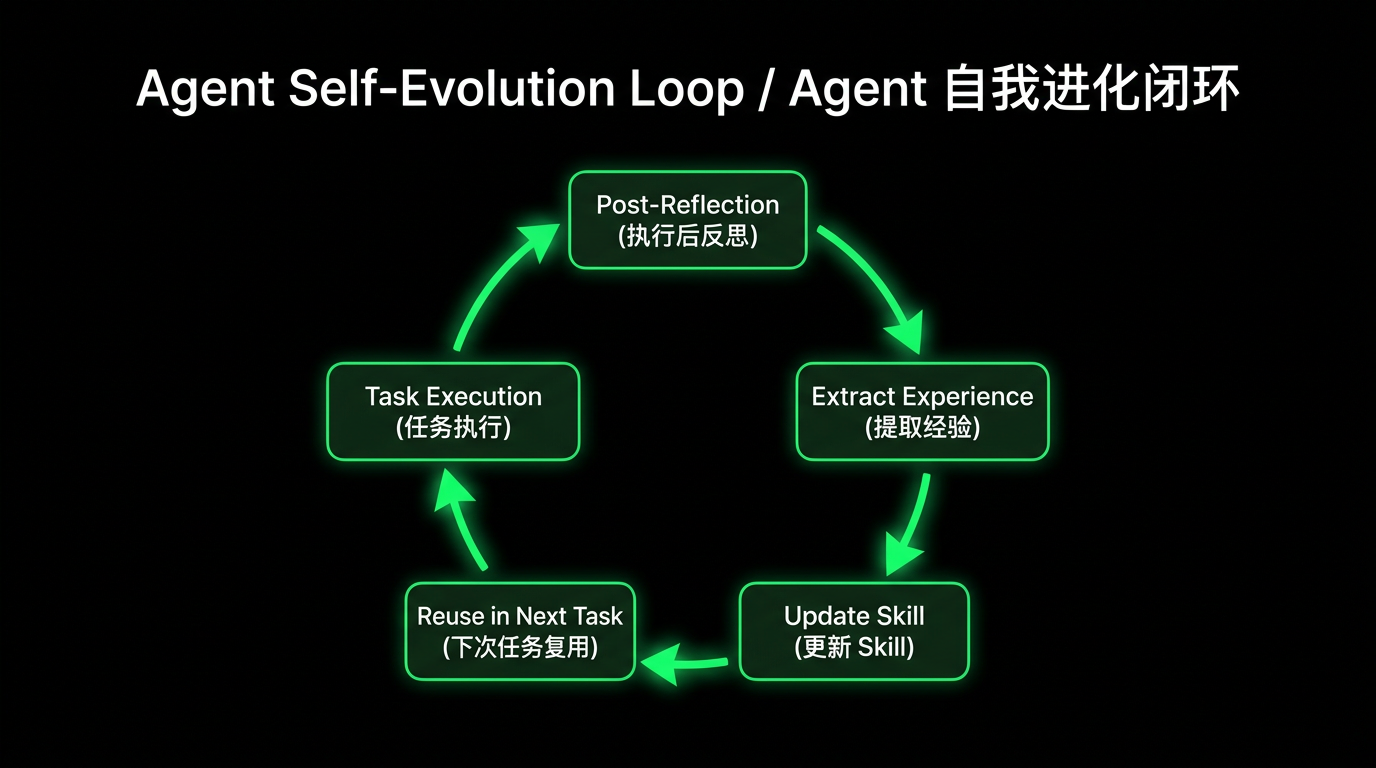
This reflection data is written to a separate task-retro.md file, which is periodically reviewed by another Pipeline Agent responsible for process improvement to update the corresponding Skill content. The entire process forms a clear evolution chain:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This closed loop gives the system self-evolution capability, corresponding to the Critic → Refiner feedback loop in Harness: every Agent mistake is a signal. If the same category of errors recurs repeatedly, it indicates a gap in the Harness itself. Rather than relying on humans to discover these gaps, let the system analyze and patch itself.
Auto Fix
During the log analysis task, we have the AI autonomously evaluate fix confidence and structurally output a confidence score for resolving the issue. We set dynamic thresholds to trigger auto-fix tasks.
The reason for introducing the confidence-score mechanism is that even with the Ultimate model, current SOTA large model capabilities cannot autonomously resolve all issues. While fully unattended Harness Engineering is the end goal, in the present moment, we must be realistic about cost control and avoid fix tasks producing large amounts of invalid code. In this ta...
Introducing QoderWork: An AI Assistant That Actually Gets Work Done
desc: QoderWork is a desktop AI assistant that operates directly on your computer
category: Product
img: https://img.alicdn.com/imgextra/i4/O1CN01K21tPZ1NxnTzJ0DfN_!!6000000001637-2-tps-1712-1152.png
time: February 12, 2026 · 3 min read
{kind=link}
Most AI assistants live inside a chat window. You ask a question, you get an answer, and then you're back to doing the actual work yourself—opening files, switching between apps, copying and pasting, formatting documents. The AI helped you think, but it didn't help you do.
We built QoderWork to change that.
QoderWork is a desktop AI assistant that operates directly on your computer. It can access your local files, connect to your tools, and execute complete workflows from start to finish. Instead of just answering questions, it sits beside you and helps you get things done.
From Chat to Action
Large language models have proven remarkably capable at understanding and generating text. But for most knowledge workers, the job isn't just about writing—it's about managing files, generating reports, coordinating across tools, and handling the dozens of small tasks that fill a workday.
Traditional AI assistants can help you draft an email. They can't help you open a local spreadsheet, analyze the data, and turn it into a presentation. That gap between "thinking" and "doing" is exactly what QoderWork is designed to bridge.
Our philosophy is simple: AI should work where you work, with your tools, in your way.
What QoderWork Can Do
Work with Your Local Files
QoderWork runs in a local virtual environment with access to folders you authorize. No uploading to the cloud, no copy-pasting back and forth. Tell it what you need, and it works directly in your file system—reading documents, organizing folders, extracting information, generating new files.
Whether it's pulling key clauses from a contract, batch-renaming files, or compiling screenshots into a document, QoderWork handles it. Think of it as a colleague sitting at the desk next to you. Drop a folder on their desk, say "help me sort this out," and it's done.
Generate Professional Documents
This is where QoderWork really shines. Its built-in Skills system produces publication-ready output across common formats: Word documents with proper formatting and structure, Excel spreadsheets with formulas and charts, PowerPoint presentations with thoughtful layouts, and PDFs with full form and page manipulation.
These aren't rough drafts—they're files you can bring to meetings or send to clients. Each format is backed by battle-tested best practices that ensure consistent, professional quality.
Connect Your Tools
Knowledge workers live in a fragmented world of apps—task managers, design tools, team docs, online platforms. Through MCP (Model Context Protocol), QoderWork integrates deeply with the services you already use.
It can check your to-do list, pull design assets, create documents in your team workspace, and orchestrate workflows that span multiple platforms. The real power isn't just automation—QoderWork understands the relationships between your tools and can work across them intelligently. Start with a task, draft the corresponding plan, gather relevant materials, and produce a complete deliverable. All in one flow.
Browse the Web
Sometimes the information you need lives on a webpage. QoderWork includes full browser automation: visiting sites, filling forms, clicking buttons, extracting data, capturing screenshots. Useful for research, testing web applications, scraping structured data, or automating repetitive online tasks.
It runs in its own sandboxed environment—secure and controlled.
Research and Retrieve
Need background for a report? QoderWork can search the web, query academic databases, and compile findings. It handles information gathering so you can focus on analysis and decisions.
Generate Images
When you need a visual, QoderWork can generate images from your description and save them directly to your project folder. Document illustrations, presentation graphics, concept designs—all without switching tools.
How We Think About Security
Giving an AI assistant access to your local files requires careful design. Security isn't a feature we added—it's foundational to how QoderWork works.
Clear permission boundaries. QoderWork only accesses folders you explicitly authorize. It won't wander through your hard drive or read files without your knowledge.
File protection first. When file deletion is needed, QoderWork moves files to a protected recovery area rather than permanently removing them. You always have a way back.
Transparent and traceable. Throughout any task, QoderWork shows you exactly what it's doing through a live progress panel. You see what's happening, what's done, and what's next—no black boxes.
A Real Workflow
Here's what this looks like in practice.
You're a product manager with a review meeting tomorrow. You tell QoderWork: "Help me prepare materials for tomorrow's product review. My project folder has recent user research and competitive analysis. I need a presentation and a detailed report."
QoderWork asks clarifying questions—who's the audience, how many slides, should it include charts? Then it reads your source materials, extracts key insights, and generates a structured PowerPoint deck and a comprehensive Word document. You can watch its progress in real time and adjust direction at any point.
When it's done, the files appear in your folder. Open them and they're ready to use.
Join the Beta
We're opening QoderWork to public beta today because we believe the best products are built with real users solving real problems. This is an early version, and we're eager to learn how you'll use it—and where it falls short.
If you're interested in an AI assistant that goes beyond chat to become a genuine work partner, visit qoder.com/qoderwork to get started.
We can't wait to see what you'll create with it.
QoderWork is now available in public beta on macOS. Windows support coming soon.