
Quickstart • MCP Server • Bash / AGENTS.md • CLI • Python API • Benchmarks
Semble is a code search library built for agents. It returns the exact code snippets they need instantly, using ~98% fewer tokens than grep+read and cutting latency on every step. Indexing and searching a full codebase end-to-end takes under a second, with ~200x faster indexing and ~10x faster queries than a code-specialized transformer, at 99% of its retrieval quality (see benchmarks). Everything runs on CPU with no API keys, GPU, or external services. Run it as an MCP server or call it from the shell via AGENTS.md and any agent (Claude Code, Cursor, Codex, OpenCode, etc.) gets instant access to any repo.
Your agent will automatically use Semble whenever it needs to find code. Instead of grepping with a keyword and reading full files, it queries in natural language (e.g. "How is authentication handled?") and gets back only the relevant context. Semble can be set up as an MCP server or as a bash tool:
Add Semble to Claude Code (requires uv):
claude mcp add semble -s user -- uvx --from "semble[mcp]" sembleUsing another agent harness? See MCP Server for setup instructions for Codex, OpenCode, Cursor, and other MCP clients.
Install Semble first, then add the code search snippet to your AGENTS.md or CLAUDE.md:
pip install semble # Install with pip
uv add semble # Or install with uvNote: for Claude Code or Codex CLI sub-agents, use the bash integration instead of, or alongside, MCP.
To update Semble, see Updating.
- Fast: indexes an average repo in ~250 ms and answers queries in ~1.5 ms, all on CPU.
- Accurate: NDCG@10 of 0.854 on our benchmarks, on par with code-specialized transformer models, at a fraction of the size and cost.
- Token-efficient: returns only the relevant chunks, using ~98% fewer tokens than grep+read.
- Zero setup: runs on CPU with no API keys, GPU, or external services required.
- MCP server: drop-in tool for Claude Code, Cursor, Codex, OpenCode, and any other MCP-compatible agent.
- Local and remote: pass a local path or a git URL.
Semble can run as an MCP server so agents can search any codebase directly. Repos are cloned and indexed on demand, and indexes are cached for the lifetime of the session. Local paths are watched for file changes and re-indexed automatically.
Requires uv to be installed.
claude mcp add semble -s user -- uvx --from "semble[mcp]" sembleAdd to ~/.codex/config.toml:
[mcp_servers.semble]
command = "uvx"
args = ["--from", "semble[mcp]", "semble"]Add to ~/.opencode/config.json:
{
"mcp": {
"semble": {
"type": "local",
"command": ["uvx", "--from", "semble[mcp]", "semble"]
}
}
}Add to ~/.cursor/mcp.json (or .cursor/mcp.json in your project):
{
"mcpServers": {
"semble": {
"command": "uvx",
"args": ["--from", "semble[mcp]", "semble"]
}
}
}| Tool | Description |
|---|---|
search |
Search a codebase with a natural-language or code query. Pass repo as a git URL or local path. |
find_related |
Given a file path and line number, return chunks semantically similar to the code at that location. |
An alternative to MCP is to invoke Semble via Bash. For Claude Code and Codex CLI, this is the only option for sub-agents, which cannot call MCP tools directly (both lazy-load MCP schemas at the top-level agent only).
To add Bash support, append the following to your AGENTS.md or CLAUDE.md:
## Code Search
Use `semble search` to find code by describing what it does or naming a symbol/identifier, instead of grep:
```bash
semble search "authentication flow" ./my-project
semble search "save_pretrained" ./my-project
semble search "save model to disk" ./my-project --top-k 10
```
Use `semble find-related` to discover code similar to a known location (pass `file_path` and `line` from a prior search result):
```bash
semble find-related src/auth.py 42 ./my-project
```
`path` defaults to the current directory when omitted; git URLs are accepted.
If `semble` is not on `$PATH`, use `uvx --from "semble[mcp]" semble` in its place.
## Workflow
1. Start with `semble search` to find relevant chunks.
2. Inspect full files only when the returned chunk is not enough context.
3. Optionally use `semble find-related` with a promising result's `file_path` and `line` to discover related implementations.
4. Use grep only when you need exhaustive literal matches or quick confirmation of an exact string.Claude Code sub-agent: Claude Code also supports a dedicated sub-agent. Run this once in your project root:
semble init
# or, if semble is not on $PATH:
uvx --from "semble[mcp]" semble initThis writes .claude/agents/semble-search.md.
Semble also ships as a standalone CLI for use outside of MCP. This is useful in scripts or anywhere you want search results without an MCP session.
# Search a local repo
semble search "authentication flow" ./my-project
# Search for a symbol or identifier
semble search "save_pretrained" ./my-project
# Search a remote repo (cloned on demand)
semble search "save model to disk" https://github.com/MinishLab/model2vec
# Find code similar to a known location (file_path and line from a prior search result)
semble find-related src/auth.py 42 ./my-projectpath defaults to the current directory when omitted; git URLs are accepted.
If semble is not on $PATH, use uvx --from "semble[mcp]" semble in its place.
To update/upgrade Semble to the latest version:
pip install --upgrade semble # with pip
uv add semble --upgrade # with uv
uv cache clean semble # for MCP users (restart your MCP client after)Semble can also be used as a Python library for programmatic access, useful when building custom tooling or integrating search directly into your own code.
from semble import SembleIndex
# Index a local directory
index = SembleIndex.from_path("./my-project")
# Index a remote git repository
index = SembleIndex.from_git("https://github.com/MinishLab/model2vec")
# Search the index with a natural-language or code query
results = index.search("save model to disk", top_k=3)
# Find code similar to a specific result
related = index.find_related(results[0], top_k=3)
# Each result exposes the matched chunk
result = results[0]
result.chunk.file_path # "model2vec/model.py"
result.chunk.start_line # 127
result.chunk.end_line # 150
result.chunk.content # "def save_pretrained(self, path: PathLike, ..."Semble splits each file into code-aware chunks using Chonkie, then scores every query against the chunks with two complementary retrievers: static Model2Vec embeddings using the code-specialized potion-code-16M model for semantic similarity, and BM25 for lexical matches on identifiers and API names. The two score lists are fused with Reciprocal Rank Fusion (RRF).
After fusing, results are reranked with a set of code-aware signals:
Ranking signals
- Adaptive weighting. Symbol-like queries (
Foo::bar,_private,getUserById) get more lexical weight, while natural-language queries stay balanced between semantic and lexical retrievers. - Definition boosts. A chunk that defines the queried symbol (a
class,def,func, etc.) is ranked above chunks that merely reference it. - Identifier stems. Query tokens are stemmed and matched against identifier stems in a chunk, giving an additional weight to chunks that contain them. For example, querying
parse configboosts chunks containingparseConfig,ConfigParser, orconfig_parser. - File coherence. When multiple chunks from the same file match the query, the file is boosted so the top result reflects broad file-level relevance rather than a single out-of-context chunk.
- Noise penalties. Test files,
compat//legacy/shims, example code, and.d.tsdeclaration stubs are down-ranked so canonical implementations surface first.
Because the embedding model is static with no transformer forward pass at query time, all of this runs in milliseconds on CPU.
We benchmark quality and speed across all methods on ~1,250 queries over 63 repositories in 19 languages. The x-axis is total latency (index + first query); the y-axis is NDCG@10. Marker size reflects model parameter count.
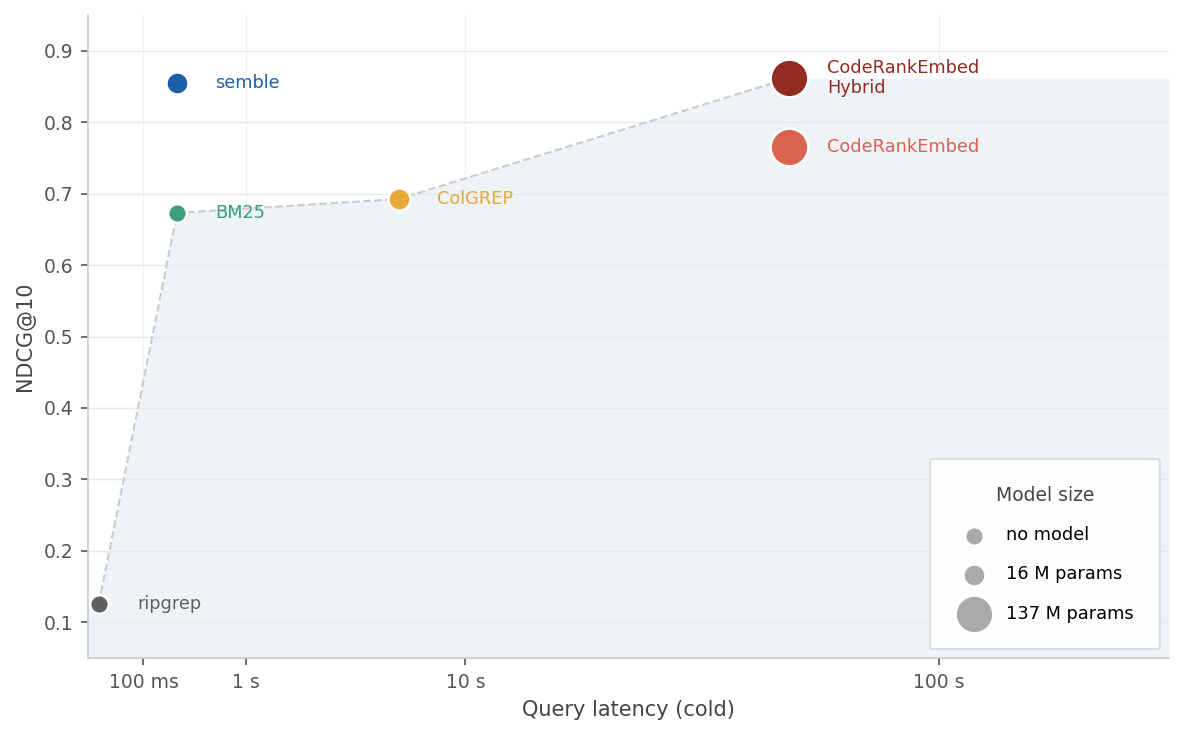
| Method | NDCG@10 | Index time | Query p50 |
|---|---|---|---|
| CodeRankEmbed Hybrid | 0.862 | 57 s | 16 ms |
| semble | 0.854 | 263 ms | 1.5 ms |
| CodeRankEmbed | 0.765 | 57 s | 16 ms |
| ColGREP | 0.693 | 5.8 s | 124 ms |
| BM25 | 0.673 | 263 ms | 0.02 ms |
| grepai | 0.561 | 35 s | 48 ms |
| probe | 0.387 | — | 207 ms |
| ripgrep | 0.126 | — | 12 ms |
Semble achieves 99% of the performance of the 137M-parameter CodeRankEmbed Hybrid, while indexing 218x faster and answering queries 11x faster. See benchmarks for per-language results, ablations, and methodology.
Agents using grep+read spend most of their context budget on irrelevant code. Semble returns only the chunks that match, keeping token usage low even at high recall.
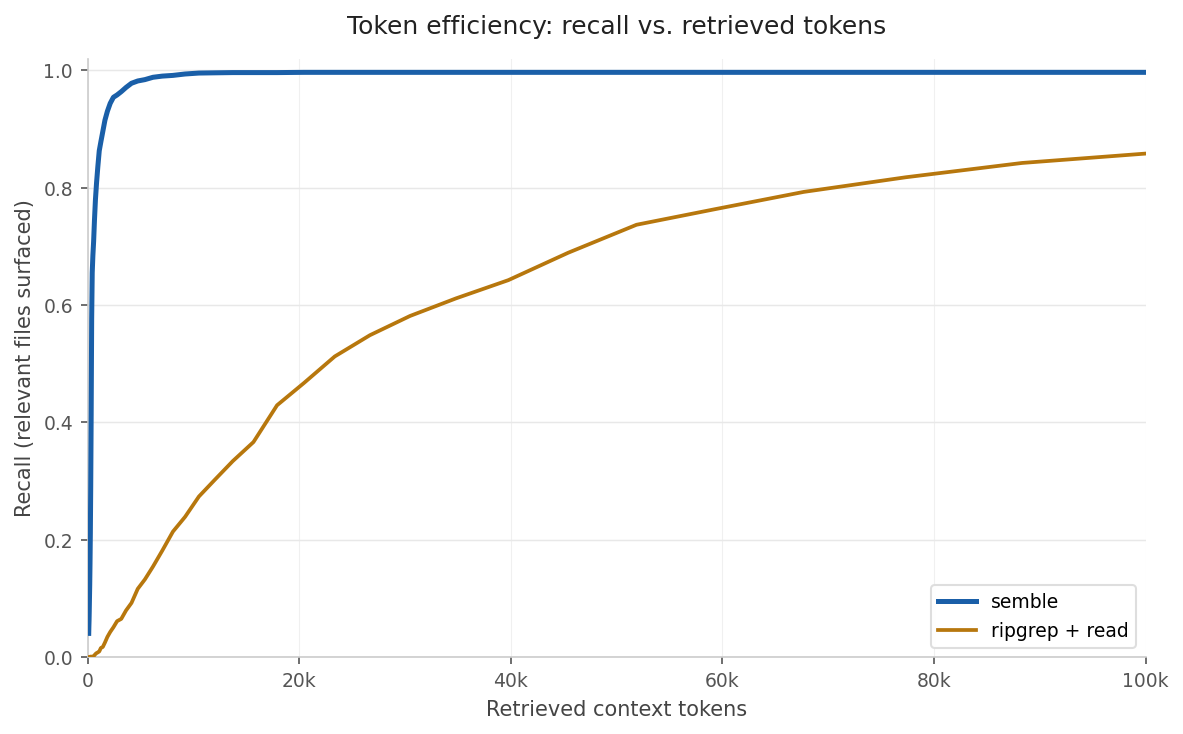
Semble uses 98% fewer tokens on average, and reaches 94% recall at a budget of only 2k tokens, while grep+read needs a full 100k context window to reach 85%. See benchmarks for details.
MIT
If you use Semble in your research, please cite the following:
@software{minishlab2026semble,
author = {{van Dongen}, Thomas and Stephan Tulkens},
title = {Semble: Fast and Accurate Code Search for Agents},
year = {2026},
publisher = {Zenodo},
doi = {10.5281/zenodo.19785932},
url = {https://github.com/MinishLab/semble},
license = {MIT}
}